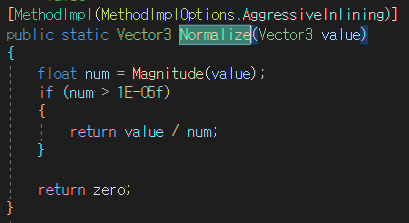
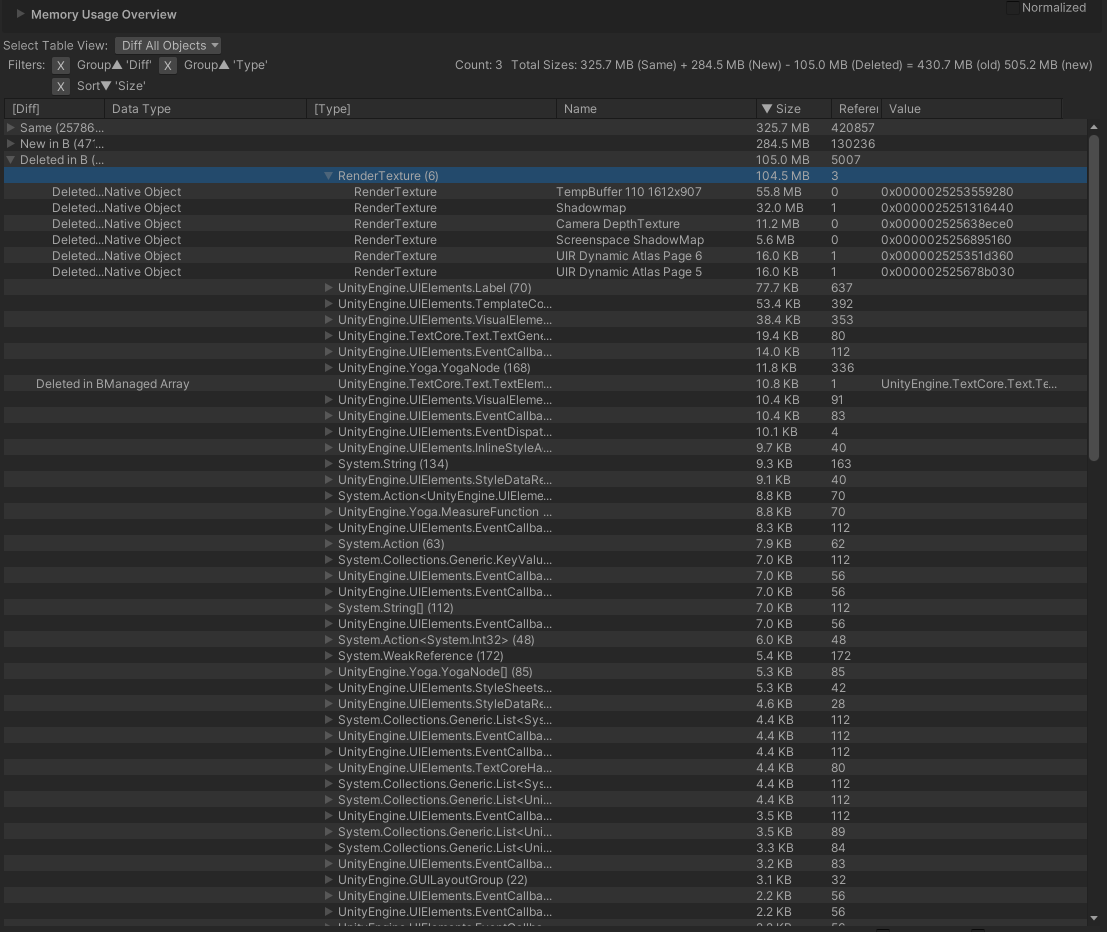
이전에 언급했던, 이번 주에 스터디 자료로 활용할 Addressables 관련 내용을 정리하였다. 추가로 AssetBundle, SBP와 현재까지의 과정에 대한 내용을 함께 구성하여 팀원들의 이해도를 높일 수 있도록 하였다. (만든 자료에서 일부 내용은 수정하여 올림)
이 글로 AssetBundle과 Scriptable Build Pipeline, Addressables에 대한 전반적인 내용을 이해할 수 있기를 바란다.
AssetBundle

Asset Bundle: 특히 모바일 게임에서, 게임에 접속할 때 다운로드 받는 것


사용해야 하는 이유 1: Google Play Store의 앱 크기 제한은 150MB (App Store는 500MB)

가끔 Google Play Store의 제한인 150MB를 초과하는 경우가 있는데, PAD(Play Asset Delivery)를 활용한 것. 최대 1GB(경우에 따라 2GB)까지 에셋 번들을 함께 다운로드 받을 수 있음. 스토어에서 다운받도록 하면 비용이 들지 않기 때문에 활용하면 좋다.
사용해야 하는 이유 2: 데이터 유동성 확보
앱을 통째로 빌드한다면 빌드 시간 소요, 스토어 검수 통과 필요, 플레이어가 업데이트 해야 함.
에셋 번들을 경우, 서버를 내리고 에셋 번들을 업데이트하면 플레이어가 게임 내에서 다운로드를 받을 수 있음. 처리에 걸리는 시간도 훨씬 적기 때문에 버그에 대해 훨씬 유연하게 대처할 수 있음.
단점: 에셋 번들 시스템을 구축하는 과정이 상당히 복잡하다.

다행인 점: 우리는 이미 에셋 번들 시스템이 구축된 상태다.
현재 사용중인 BuildPipeline의 문제점: 압축 방식에 따라 빌드 과정이 분리되어 종속성이 제대로 설정되지 않는다.

종속성: Material이 포함된 Prefab을 Load할 때, 필요한 Material을 먼저 Load하고 Prefab을 로드해야 한다. 그렇지 않으면 Magenta 색을 볼 수 있음. (이 경우 Prefab이 Material에 종속성이 있는 것임)

LZ4 방식의 빌드 과정과 LZMA의 빌드 과정이 분리되어 Dependencies가 제대로 설정되지 않음.
→ Asset의 복제가 일어남. (참조)
LZMA: zip, 7z 등에 사용되는 압축 방식으로, 압축률이 높지만 로딩 속도가 느림.
LZ4: LZMA에 비해 압축률은 낮지만 로딩 속도가 빠르고 효율적이기 때문에, 다운로드를 받을 때만 LZMA로 압축된 번들을 받고 다운받을 때 LZ4로 Recompress하여 디스크에 저장함.
UnCompressed: 비압축 방식으로, 빌드 속도는 빠르겠지만 용량이 굉장히 커지기 때문에 권장하지 않는 방법임. UnCompress보다 LZ4가 첫 로딩 속도가 빠른 것 같다는 내용이 있었는데, 아마 처음 실행할 때 LZ4로 압축하는 과정을 거치는 것이 아닐까 싶음.
Scriptable Build Pipeline
Scriptable Build Pipeline: BuildPipeline보다 유연성 있게 빌드할 수 있도록 제공하는 패키지.
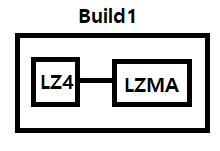
ContentPipeline을 사용하면 압축 방식과 상관없이 빌드가 한꺼번에 이뤄지기 때문에 Dependencies의 손실이 없다.

기존에 사용하던 BuildPipeline과 큰 차이점이 없어서 전체 과정의 일부를 변경하는 것으로 적용되었음. (대략 주황색 정도)
문제점: Shader Stripping이 BuildPipeline과 다른 방식을 거치는 것으로 보인다.
BuildPipeline: Graphics 세팅의 FOG_EXP, FOG_EXP2, SHADOWS_SHADOWMASK를 끄면 정상적으로 Shader Stripping이 이루어진다.
ContentPipeline: Graphics 세팅의 FOG_EXP를 끄면 정상적으로 Shader Stripping이 이루어지지만, FOG_EXP2와 SHADOWS_SHADOWMASK는 꺼도 Shader Stripping이 이루어지지 않는다.
BUG? (추가적인 확인 필요)
Bug - Addressable and shader variants - Unity Forum → SBP를 사용하는 Addressables에서 Graphics Setting의 Shader Stripping이 안 된다는 사람이 있음.
Question - SBP don't strip shader variants? - Unity Forum
→ Scriptable Build Pipeline에서 Shader Stripping이 제대로 되지 않는다는 내용의 글
→ 기존과 비교해서 삭제되지 않은 것을 수동으로 삭제해주는 것으로 해결했다고 함.
우리도 약 210MB → 약 90MB로 상당 부분 감소함. (화요일)
하지만 여전히 기존의 약 70MB보다는 30%가량 큰 문제가 있음.
대부분의 용량은 Nature Shaders의 Shader에서 차이가 나는데, 이 용량만 줄인다면 Shader의 용량이 기존보다 감소함.
전체 용량으로 보았을 때는 기존의 전체 용량보다 약간이지만 작은 것을 확인하였음. (AnimationClip의 수가 30% 감소하였고, 이외에도 조금씩 변화가 있었음)
다만 바로 적용시키는 것은 꺼려지는데, Nature Shaders의 용량이 변하는 이유를 아직 확인하지 못했기 때문임.
1. IPreProcessShader에서 Shader Stripping이 된 이후에 Shader의 키워드들을 확인했고, 각 Shader에서 사용되는 키워드는 동일한 것을 확인할 수 있었음.
2. 각 Pass에서 사용되는 키워드도 동일한 것을 확인하였음. (BuildPipeline에서는 가끔 Pass에 1개의 키워드가 적게 들어오는 경우가 있었는데, ContentPipeline에서 이 키워드를 삭제하니 용량은 전체적으로 작아졌지만 그래픽에 문제가 생겼고, Grass의 경우 여전히 기존보다 2배 이상 컸음)
3. Log Shader Compilation을 기록해보았으나 BuildPipeline, ContentPipeline 각각의 빌드에서 컴파일 된 셰이더의 컴파일 내용은 완전히 동일했음 (특정 맵 기준)
4. 프레임에 따라 옵션이 바뀌는 기능을 끄고 해봤으나 용량은 동일했음
5. RenderDoc으로 각 경우에서 사용된 Shader를 비교해보았으나 동일한 것으로 추정됨. (Line 수로 판단)
게임 내에서 로드된 Shader에 포함된 정보들을 출력해보았으나 유의미한 결과는 얻을 수 없었음.
6. 에셋에 포함된 Shader에 대한 정보를 볼 수 있는 툴들을 다수 활용해보았으나 ShaderX로 잠겨있어서 내부 정보를 얻을 수 없었음.
7. SBP에 Build Logging에 대한 내용도 있으나 Shader로 검색한 결과 유의미한 결과를 얻을 수 없었음.
→ BuildPipeline을 사용할 때보다 용량이 크다는 문제점은 인식했지만, 원인을 규명하기가 어려움
용량 차이의 문제는 ShaderX를 사용하는 Nature Shaders만 두드러지게 나타남. 나머지는 용량이 동일하거나 차이가 있다고 해도 미미한 수준이었던 것 같음. (Nature Shaders에 Standard가 포함되어 있는 것도 약간 의문이며, 이 Standard에서도 용량 차이가 나타남)
1개의 Shader에서 8개의 Variants를 생성하는 Keyword가 있었는데, 영향은 적지만 차이점을 이해할 수 있는 단서가 될 수도 있을 것 같음. (왜 삭제가 되지 않았는지?)
Shader Stripping에 대한 Insight를 얻어서 현재 사용 중인 Shader Stripping을 더욱 최적화 할 수 있을 것 같음.
현재: 일부 Scene을 돌면서 수동으로 정리한, “전체 Shader에서 사용하지 않는” Keyword들을 삭제해 줌.
개선 가능: Scene들을 돌면서 나온 Log에서 각 Shader에 사용되는 Keyword, 혹은 Variants를 자동으로 추출하여 저장하고, 이를 제외한 Keyword들을 삭제해줌 (자동화, 각 Shader에 대한 최적화)
Addressables
들어가기 전에…
Addressables는 빌드할 때 Scriptable Build Pipeline을 사용한다고 하는데, Addressablse로 바꾼다고 해도 현재와 동일한 문제가 발생할 가능성이 있음. (Shader Stripping 관련)
Addressables: Unity에서 제공하는 Asset Bundle 빌드에 사용하는 최신 Package
[Addressables의 장점]
1. 경로 등에 영향을 받지 않는 Address를 사용하여 유연하게 사용 가능 (기본값은 실제 Path)
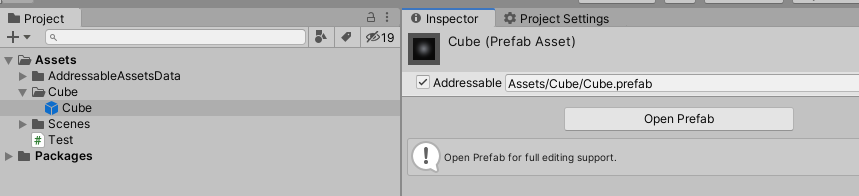
Addressables 패키지를 받으면 Asset에 위와 같이 Addressables이라는 체크 박스가 생기고, 체크 박스를 체크하면 각 Asset이 고유한 Address를 가질 수 있게 됨. 기본값은 에셋의 실제 Path이며, Adress는 Asset을 수정하거나 경로를 변경해도 유지되기 때문에 실제 Path를 사용하는 것보다 유연하게 사용이 가능함
Asset을 Load할 때 Address로 호출하기 때문에 현재 방식을 그대로 사용할 수 있을 것 같음
2. Addressables 창에서 에디터의 Asset/AssetBundle 중 어떤 것을 로드할지 선택이 가능함

우리는 AssetBundle을 사용하지만 구현되어 있는 기능
3. 종속성 관리를 자동으로 해줌
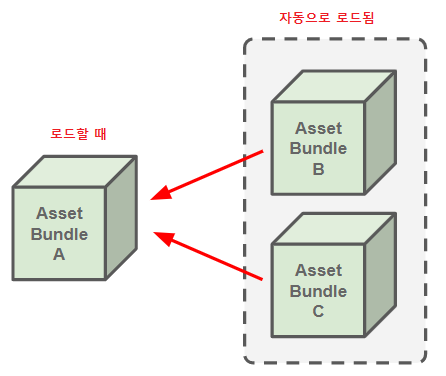
AssetBundle을 사용하면 AssetBundleA를 로드할 때, 종속성이 있는 다른 번들들을 미리 로드해야 하기 때문에 각 번들의 Dependencies를 체크하고 로드하는 작업을 해줘야 하지만(우리는 구현되어 있음), Addressables는 이것을 자동으로 처리해줌
4. 참조 카운터를 사용하여 메모리 관리의 효율성 확보 가능


【Unity】Addressableアセットシステム入門 - 3つのメリットと基本的な使い方を紹介 - LIGHT11 (hatenadiary.com)
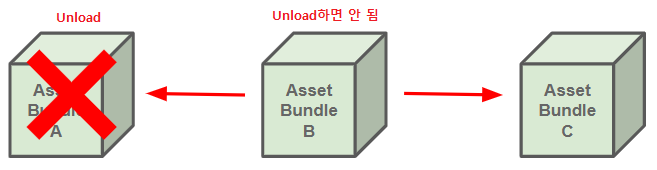
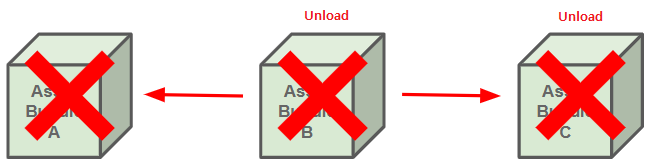
보시다시피 AssetBundle의 메모리를 제대로 관리하는 것은 번거로운 일입니다. 내부적으로 참조 카운터를 갖는 등의 구현이 필요합니다.
Addresssables에는 이러한 종속성을 기반으로 하는 참조 카운터 메커니즘이 포함되어 있습니다. 즉, 에셋 번들을 한 번 로드하는 경우 한 번 언로드 해야 한다는 규칙을 따른다면 종속성을 포함하여 깨끗한 메모리를 확보할 수 있습니다.
→ Bundle 간에도 참조 카운터를 가지고 있는 것으로 추측됨.
어드레서블 에셋 시스템으로 메모리 최적화하기 | Unity Blog
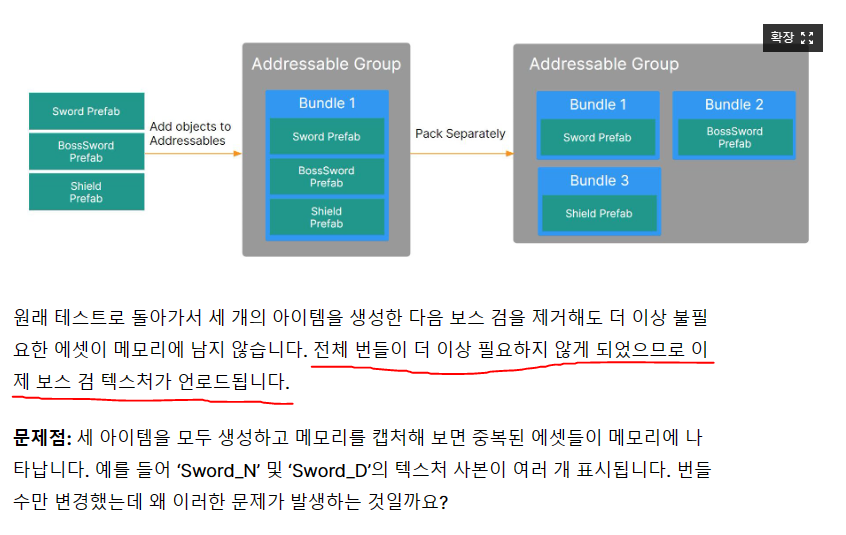
AssetBundle 내에서 사용하는 Asset이 없다면, 자동으로 번들을 해제해주는 것으로 보임.
즉, 번들 내 에셋의 수를 적게 유지하는 것이 효과적인데, 이러면 에셋 번들의 메타 데이터가 많아지는 문제가 발생함.

Unity에서는 이를 위한 해결책도 제시함.

함께 로드되는 Asset들을 분석해서 하나의 번들로 묶어주는 것임.
참조 카운터, 메모리 관련 추가 내용
[Unity3D] Addressable 특징 메모 (tistory.com)
→ InstantiateAsync가 Ref-Count를 관리하여 사용되지 않는 번들을 자동으로 해제한다고 함.
→ 기본 규칙은 번들이 너무 세부화될 수 있기 때문에 Custom Rule을 사용하는 것이 좋다고 함.
어드레서블 에셋 시스템 - 개념: 에셋 로드와 생성 및 해제 (tistory.com)
→ "만약 Addressable의 InstantiateAsync함수로 생성했다면 Release 시 Ref Count가 0이 될때까지 해제하지 않고 기다려준다.”
메모리 관리 개요 | 어드레서블 | 1.21.15 (unity3d.com)
AssetBundles have their own reference count, and the system treats them like Addressables with the assets they contain as dependencies. When you load an asset from a bundle, the bundle's reference count increases and when you release the asset, the bundle reference count decreases. When a bundle's reference count returns to zero, that means none of the assets contained in the bundle are still in use. Unity then unloads the bundle and all the assets contained in it from memory.
In this example, the asset isn't unloaded at this point. You can load an AssetBundle, or its partial contents, but you can't unload part of an AssetBundle. No asset in unloads until the AssetBundle is unloaded.
→ 에셋을 Release하더라도 바로 메모리에서 해제되는 것은 아님. 에셋 번들의 Asset을 부분적으로 Unload할 수는 없으며, 번들의 Refenrence Count가 0이 되면 번들이 해제되며 이때 Asset들의 메모리가 해제된다.
The exception to this rule is the engine interface [Resources.UnloadUnusedAssets]. Executing this method in the earlier example causes to unload. Because the Addressables system isn't aware of these events, the Profiler graph only reflects the Addressables ref-counts (not exactly what memory holds).
→ Resources.UnloadUnusedAssets는 예외적으로 번들에서 사용되지 않는 Asset들을 부분적으로 Unload 가능하다고 함. 단, 이는 Addressables에서 제공하는 프로파일러가 인지하지 못하기에 실제 메모리와는 다른 정보가 표기될 수 있다고 함.
Event Viewer | Addressables | 1.21.15 (unity3d.com)
The window shows when your application loads and unloads assets and displays the reference counts of all Addressables system operations.
→ 위에서 얘기한 프로파일러는 Event Viewer인 것으로 보이고, 빌드할 때 Send Profiler Events를 체크하여 볼 수 있다고 함. 참조 카운터와 Asset의 Load, Unload를 확인할 수 있다고 함.
*******************
(추가 내용)
Addressables는 사용만 제대로 한다면 Asset의 Reference Count도 관리해준다.
어떤 Prefab에서 다른 번들의 Sprite를 참조하고 있는 경우, Prefab을 Release해서 Sprite의 Reference Count가 0이 된다면 Sprite도 자동으로 해제해준다.
이 장점 하나만으로도 Addressables를 사용할 가치는 충분하다고 생각된다.
다음 글에서 이 내용에 대해서 다루겠다.
*******************
기타
Group, Label
Pack groups into AssetBundles | Addressables | 1.21.15 (unity3d.com)
모든 Asset은 Group에 속하고, Label을 추가하여 번들을 묶는 방식을 제어할 수 있음.
Pack Together: 그룹 내의 모든 Asset을 하나의 번들로 묶음
Pack Separately: 그룹 내의 모든 Asset을 각각의 번들로 묶음
Pack Together By Label: 그룹 내의 모든 Asset을 Label마다 1개의 번들로 묶음
Content Catalog
Content catalogs | Addressables | 1.21.15 (unity3d.com)
Asset의 실제 위치와 Address를 매핑하는 파일.
Hash파일을 통해 Content Catalog가 변경되면 다운로드하게 만들 수 있음.
Address로 Asset을 Load → Content Catalog에서 Address에 해당하는 Asset을 찾아오는 듯.
Internal Asset Naming Mode
Addressables FAQ | Addressables | 1.19.19 (unity3d.com)
Content Catalog 등에 저장되는 Asset의 ID를 결정하는 방법을 정할 수 있음.
Full Path: 파일의 전체 경로로, 개발 중에만 사용하는 것을 권장하는 듯.
Filename: 파일의 이름으로 식별하는 것. 동일한 이름을 가진 Asset을 만들 수 없음.
GUID: GUID로 식별
Dynamic: Release에 추천되는 사용법으로, 식별 가능한 가장 짧은 GUID를 만들어서 저장하기 때문에 AssetBundle과 Catalog의 크기도 감소하고, 런타임 메모리 오버헤드도 줄어든다고 함.
Addressables에서 CRC 사용과 로딩 속도 관련 문제
Addressable Load Performance - Unity Forum
Bug - Addressables - Extremely slow load time - Unity Forum
Are CRC checks worth the insane overhead? - Unity Forum
Addressable에서 로딩 속도가 굉장히 느리다는 얘기가 있는데, CRC를 사용하면 속도가 굉장히 느려지고, CRC를 끄면 AssetBundle을 사용할 때와 동일하다는 것으로 보임.
Unity Technologies는 CRC를 상황에 따라 나누어 사용하는 것을 권장하는 것으로 보임.
참고할만한 내용

Configure your project to use Addressables | Addressables | 1.21.15 (unity3d.com)
AssetBundle → Addressables
hammerimpact (Hammer Impact) - velog
Addressables 1.21.12 문서를 한국어로 번역한 블로그
Addressable Assets Systemをちゃんと導入するための技術検証まとめ – てっくぼっと! (applibot.co.jp)
Addressables의 기술적인 부분을 분석한 글
유니티(Unity) - Addressable(어드레서블) 사용법(8). 서버에서 다운로드하기 2편[Catalog 이해] : 네이버 블로그 (naver.com)
Addressables 카탈로그 버전 관리 관련 내용
'개발 > 공부' 카테고리의 다른 글
| JetBrains Rider의 장점을 활용해서 효율적인 개발하기 (0) | 2023.09.16 |
|---|---|
| 메모리 관리에 대한 탐구 (9) - Addressables와 메모리 관리 (0) | 2023.08.20 |
| 메모리 관리에 대한 탐구 (7) - 에셋의 중복과 Scriptable Build Pipeline (0) | 2023.08.12 |
| 메모리 관리에 대한 탐구 (6) - 에셋 번들의 이해 (0) | 2023.08.11 |
| [유니티] Vector3의 Normalize 방법 별 성능 테스트와 오버헤드 (0) | 2023.08.05 |