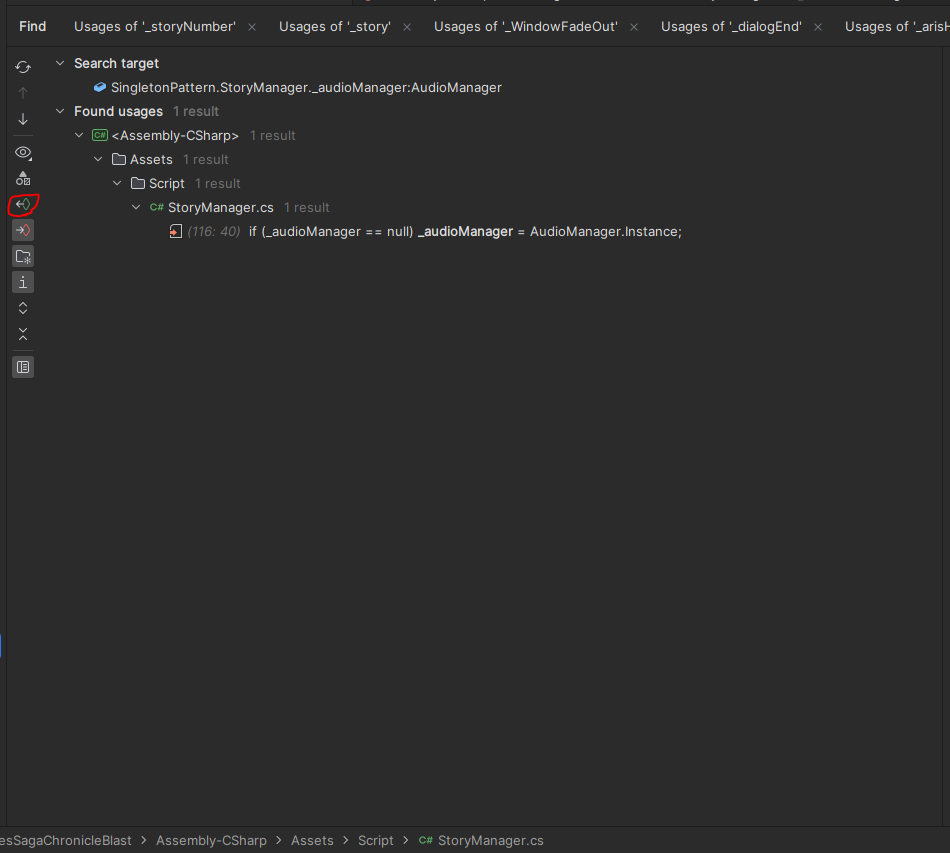
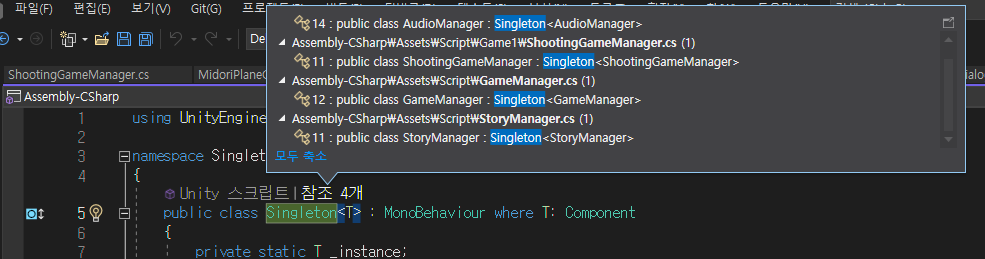
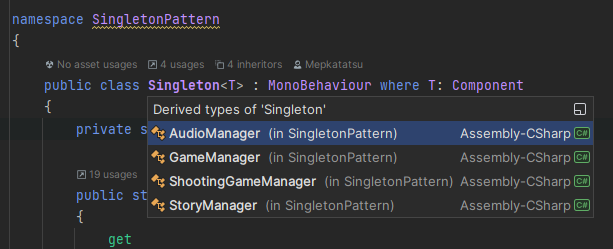
이 데이터들을 csv, json, binary 각각 어떤 방식으로 사용하는 게 효율적일지 궁금하여 테스트해보았고, 이 결과를 정리해보고자 한다.
예를 들면 스토리 대사 같은 데이터들이 필요할 수 있다. 보통 이런 건 구글 스프레드 시트에서 데이터를 작성, 관리하여 파일로 변환해 유니티로 가져와 사용한다.
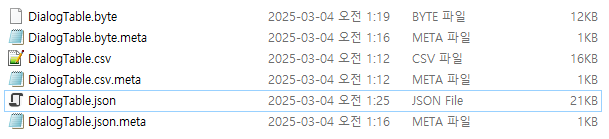
위 내용을 csv로 저장하면 이런 식으로 저장된다. 쉼표로 데이터들이 구분되며 줄줄이 나열되는 방식이다.
위 데이터들을 코드로 나타내면 이런 식으로 나타낼 수 있을 것이다. (밑의 Synchronize 부분은 신경쓰지 않아도 괜찮다)
이 데이터를 json으로 Serialize하면 이런 느낌으로 저장된다.
각 변수들의 이름과 값을 저장하고, 나중에 읽을 때 이름이 같은 걸 찾아서 해당 값을 가져오는 방식이다.
위에 있는 함수는 Json으로 변환하는 함수인데, 매우 간편하다. Newtonsoft.Json을 활용하면 List 데이터도 손쉽게 Serialize 가능하다.
아래 함수는 Binary로 데이터를 기록하기 위한 함수인데, 말 그대로 Binary로 저장하는 거다보니 파일을 직접 열어서 읽기는 어렵다.
직접 파일을 열어보면 대략 이런 느낌이다.
아무튼 각 함수들은 매우 간단하고 단순하게 csv, json, byte 파일로 각각 저장하게 만들어놨다.
CSV를 읽는 함수를 먼저 만들었는데, 빠른 테스트를 위해 대충 만들었는데 일단 csv 파일의 모든 라인을 읽고, 쉼표로 분리해서 각 데이터를 parsing하고 DialogData로 만들어서 저장하는 방식이다.
Json을 사용하면 로딩도 매우 간편하다.
Binary는 이런 식으로 CSV와 비슷하게 읽어오도록 했다. 주의할 점은 읽을 때 데이터가 얼마나 들어있는지 모르기 때문에 쓸 때 미리 몇 개의 데이터가 있는지를 저장해놔야 한다는 점이다. Write와 Read를 동일한 방식으로 만들어주면 어렵지 않게 Binary 형식으로 읽고 쓸 수 있다.
자 이제 측정의 시간이다. Stopwatch로 단순히 10000번 반복하여 각각에 걸리는 시간을 측정해보았다.
결과는 Binary > CSV > Json 순서로 소요시간이 짧았다.
심지어 저장 용량도 Binary > CSV > Json 순으로 작았다.
결론은 Binary가 가장 적합한 것으로 보인다. 다만 테이블을 바로 Binary로 가져올 수는 없으니 구글 스프레드 시트에서 테이블을 관리하고, CSV로 받아와야 할 것이다. CSV도 속도 측면에서 큰 차이는 없으니 빌드해서 나갈 때 정도만 Binary 파일로 바꿔서 나가기만 해도 괜찮지 않을까 싶다.
유니티로 모바일 게임을 개발하다보면 메모리 용량을 확보해야 하는 상황이 온다. (여기서 말하는 메모리는 RAM이다) 이뿐만 아니라, 디스크 용량 확보도 중요한 요소이다. 게임의 용량이 작은 것을 유저들이 더 선호하기도 하며, 다운로드 용량이 클수록 부담해야 하는 비용도 늘어나기 때문이다.
일례로, AssetBundle 다운로드에 AWS를 많이 사용하게 될 텐데, AWS의 S3 요금제를 살펴보면 위와 같다.
많이 사용할수록 가격이 감소하지만, 최저 요금을 기준으로 봐도 1GB당 $0.108로 2024년 10월 27일 현재 환율로 150원 정도의 비용이 들어가는 셈이다.
10만명의 유저가 다운로드를 받는다고 가정했을 때 다운로드 용량을 1GB 줄이는 경우, 최저 요금을 기준으로 봐도 $10,800, 현재 환율로 약 1500만원을 절약할 수 있다.
특히 모바일 게임은 업데이트를 자주 하기 때문에 다운로드 용량을 줄이면 지속적으로 비용을 절감하는데 크게 도움이 될 것이다.
에셋 최적화는 사실 대부분 압축인데, 아주 조금일지라도 퀄리티 저하가 발생할 수 있다.
그러나 최적화는 불가피하게 해야 하는 경우가 많기 때문에 사람이 인지하지 못할 정도의 퀄리티 저하를 감수하면서 용량을 적당히 줄일 수도 있고, 인지 가능한 정도의 퀄리티 저하를 감수하며 용량을 크게 줄일 수도 있다.
아트팀에서는 이런 퀄리티 저하를 못마땅하게 여길 가능성이 높기 때문에, 최적화로 인한 퀄리티의 변화에 대해 어느정도 선까지 최적화를 해도 괜찮을지 아트팀과 협의를 할 필요가 있을 것이다.
나는 현재 참여 중인 프로젝트에서 에셋 최적화/압축을 통해 아래와 같은 효과를 볼 수 있었다. (어느 정도는 최적화가 되어있던 프로젝트이다.)
1-1. ASTC - 텍스처 압축 방식이 굉장히 많은데, 오늘날에는 ASTC 포맷이 제일 좋다는 것 같다. AOS, iOS 가리지 않고 다 쓸 수 있으며 웬만한 구기기가 아니면 다 적용이 되기 때문이다. 특히나 최신 (내가 확인한 것으로는 2022.3 이상 버전) 버전에서는 Alpha 채널을 사용하는지 아닌지도 알아서 판단해서 압축을 해주기 때문에 사용도 엄청나게 간편하다. 특히나 용도에 따라서 압축을 얼마나 할 것인지를 유동적으로 조절할 수도 있기 때문에 ASTC 포맷을 사용하는 것을 추천한다.
4x4 block ~ 12x12 block의 포맷이 있는데, 압축할 때 1블럭의 크기를 어느 정도로 할 것인지 정할 수 있는 셈이다. 4x4 block을 했을 때 가장 퀄리티가 좋고, 12x12 block을 했을 때 가장 압축 효율이 좋다.
4x4 block의 경우에는 압축을 하지 않았을 때와 퀄리티 차이를 찾기가 어려울 정도로 퀄리티가 좋기 때문에, UI에 표시되는 Sprite의 경우는 4x4 block으로 설정하고, 이외에는 10x10 block으로 일괄 설정을 해놓으면 편리하다. 물론 용도에 따라 더 세분화를 하면 퀄리티와 효율을 더 챙길 수 있을 것이다. 때문에 이런 용도에 따라서 에셋을 폴더 별로 분리해놓으면 관리하기가 매우 수월하다.
코드를 하나 만들어서, 전체 파일을 돌면서 jpg, png 등등 파일에 대해서 TextureImporter를 가져오고 세팅해주면 된다. 아마 찾아보면 참고할만한 코드들이 있을 것이다.
1-2. Mipmap - Mipmap은 3D 게임에 주로 쓰이는데, 멀리 있는 텍스처에는 저해상도 텍스처를 적용해주는데 사용된다. 이렇게 하면 대역폭도 절약할 수 있고, 고해상도 텍스처를 보여주는 것보다 퀄리티가 오히려 좋게 보일 수도 있다. 단점은 미리 생성을 해놓기 때문에 텍스처 크기가 33% 늘어난다는 것이다. 때문에 UI에 사용되는 경우와 같이 텍스처를 멀리서 보여줄 일이 없다면 꺼놓는 것이 메모리와 디스크 용량을 절약할 수 있는 방법이다.
1-3. Read/Write Enabled - 텍스처를 코드 상에서 읽고 쓰며 변경해준다면 필요할 수 있는 기능이지만, 대부분의 경우는 필요없을 것이다. 이게 켜지게 되면 GPU 메모리뿐만 아니라 CPU 메모리에도 텍스처가 할당되어 메모리 용량을 2배 차지하게 된다. 아마 폰트를 Dynamic으로 설정한 경우, 읽고 쓰는 기능이 필요하여 이 기능이 자동으로 켜지고, 때문에 메모리 용량을 2배로 차지하는 것 같다. (때문에 폰트 Texture에서는 켜고 끄는 기능을 지원하지 않는 것 같고, 아마 Static으로 해놓는다면 용량을 2배로 차지하지 않을 것 같다.)
2-1. 오디오 압축: Compression Format을 Vorbis로 하고, Quality를 40 정도로 하면 용량은 크게 줄어들지만 오디오 퀄리티에는 크게 영향이 없다. (아마 경우에 따라 다를 것이다) 좋은 퀄리티로 들려줘야 할 사운드가 있다면 따로 설정해놔도 좋을 것이다. Load type은 대부분 Decompress On Load로 충분한 것 같다. 메모리를 상대적으로 많이 차지하기는 하지만, 다른 옵션의 경우 압축을 지속적으로 해제하면서 사용할 거라 CPU에 약간 부하를 줄 수 있을 것이다. 메모리가 부족한 게 아니라면 Decompress On Load로 해도 괜찮을 듯 하고 메모리를 줄여야 한다면 용량이 큰 BGM의 경우 Streaming으로 설정해주면 좋을 것 같다. 다른 옵션들은 압축을 해제하는데 시간이 약간 걸려서 사운드 타이밍이 중요한 효과음의 경우는 용량도 작으니 Decompress On Load를 사용하는 것이 좋겠다.
3-1. Mesh 압축: Mesh 압축에는 2가지 방식이 있는데, Vertex Compression과 Mesh Compression이다. Vertex Compression은 전역적으로 적용되는 Mesh 압축인데, Player Settings에서 설정이 가능하고, 기본적으로 켜져있다. 유니티에서 권장하는 압축 방식이 버텍스 압축이다. 아마 실제로 버텍스의 수를 줄이는 것 같아서 GPU 성능이 약간 향상될 수도 있다는 것 같다. 압축 효율은 경우에 따라 다르지만 대략 30% 정도 줄어드는 것 같다. 단, Vertex Compression은 제한 사항이 많은데, Mesh가 Skinned Mesh면 적용이 안 되고(Skinned Mesh Renderer에서 사용되는 경우) Read/Write Enabled가 켜져있으면 안 되는 등의 조건이 있다. (자세한 내용은 유니티 Documentation 참고) 또, Mesh에서 직접 Mesh Compression을 설정하는 경우에도 적용되지 않는다.
Mesh Compression은 Mesh에서 직접 설정을 하는데, Low, Medium, High 3가지 옵션이 있다. Skinned Mesh거나 Read/Write Enabled가 켜져있어도 적용되는 것 같다. 대략 Low일 때 47% 정도 감소, Medium일 때 53% 정도 감소, High일 때 60% 정도 감소? 대략 이 정도로 용량이 줄어들었던 것 같다. 메시에 따라 다르게 적용될 수 있으니 대략적인 경향만 참고하면 좋을 것 같다.
Mesh Compression은 메모리에는 영향을 끼치지 않는다고 되어있다. 찾아보면 메모리 용량도 줄었다는 얘기가 있는데 실제로 어떠한지는 모르겠다. 다만 얘기로는 데이터 상에서 압축을 해놓고, 사용할 때 압축을 해제하는 방식이라는 듯. 때문에 최초 로딩 시에 시간이 소요될 수 있다고 하는데 딱히 체감할 정도는 아니었다. 압축 정도가 높을수록 모델 퀄리티에 영향을 주는데, High로 압축하는 경우 Vertex가 많은 부분, 특히 캐릭터의 입술이 부분이 다소 일그러지는 모습을 볼 수 있었다. Medium으로 압축해도 High와 용량에는 큰 차이가 없고, Medium의 경우에는 압축을 하지 않은 경우와 퀄리티 차이가 크게 없었기 때문에 Medium으로 일괄 압축을 적용한 상태이다.
Mesh Compression을 변경하는 경우, 모델을 다시 Import하기 때문에 에디터에서 시간이 많이 소요될 수 있다는 점을 참고하길 바란다. (대략 2만개의 모델에서 1~2시간 정도 소요되었던 것 같다.)
5-1. 불필요한 Dependencies 제거하기: 예를 들면... (우리 프로젝트의 예시지만) 대부분 번들에서 Shader 번들을 참조하는데, Shader 번들에 누군가가 만들어놓은 Material이 Effect 번들의 Texture를 참조하고 있고, 이 Effect 번들에서는 각종 몬스터의 Texture를 참조하고 있다고 하면, 대부분 번들에서 Shader - Effect - 각 Monster들에 대한 Dependencies를 갖게 되고, 이건 불필요한 참조 관계 데이터를 저장하게 될 뿐 아니라, 로드할 때도 굉장히 비효율적이게 될 것이다. (Dependencies가 있는 번들들을 미리 로드할 테니 말이다.) 이 부분은 우리의 경우 약간의 에셋 중복이 발생하더라도 복제해서 각 번들에 넣어주는 방식으로 해결했다.
5-2. 많은 번들에서 참조하는 에셋을 Bundle에 포함시켜주기: 특정한 에셋에 대해, 번들이 지정되어 있지 않은 경우, 이 에셋에 Dependency를 가지는 번들에 복사되어 들어간다. 그런데 이 에셋이 용량이 큰 경우거나 많은 번들에서 참조하는 경우에 문제가 발생할 수 있다. 예를 들어서 1MB짜리 텍스처가 있다고 치고, 번들 A, B, C, D, E, F, G 총 7개의 번들에서 이 텍스처를 사용한다고 하면, 각각의 번들에 하나씩 들어가기 때문에 7MB만큼 디스크 용량이 늘어나게 될 것이다. 또, 이 번들들에 들어간 텍스처는 각기 다른 에셋으로 취급되기 때문에 이전에 다루었던 메모리 중복도 발생할 수 있다. 그러나 이 1MB짜리 텍스처를 H라는 번들에 명시적으로 포함시켜주면, A B C D E F G 각 번들은 H 번들에 대한 Dependency를 갖게 되고, 디스크에서 차지하는 용량은 1MB가 되며 메모리 상에서 중복도 일어나지 않을 것이다.
이건 굉장히 막연한 부분이지만, 가장 확실한 방법이기도 하다. 일례로 내가 참여하고 있는 프로젝트에서 용량이 큰 번들들을 하나씩 체크하고 있었는데, 개당 5.3MB에 달하는 bmp 파일이 디스크 상에서 총 약 800MB 가량을 차지하고 있었다. 맵 관련 텍스처로 보여서 맵 담당하시는 분께 여쭤보니 splat 맵이라고, 맵 만들 때 사용하시는 툴에서 데이터를 뽑아서 유니티에 옮길 때 1번만 사용하는 파일이라고 하셨다. 즉, 지워도 된다는 말이다. 아직 서비스 전이니 굳이 말하자면 문제는 아니었지만, 이런식으로 눈 먼 파일들이 게임에 포함되는 경우가 꽤 많을 것 같고, 아직도 있을 것 같다. 하나하나 체크하기가 힘들어서 그렇지. ㅋㅋ... 용량이 큰 번들들을 확인하면서 용량이 큰 불필요한 파일들을 걸러주는 것도 꽤나 큰 효과를 볼 수 있을 것이다.
이건 메모리 용량을 줄이는 데에도 아주 효과적인데, 알고보니 메모리 용량이 줄어드는 만큼 디스크 용량도 줄일 수 있는 방법이었다. Shader 용량이 총 350MB 정도 된다고 쳤을 때, Shader Variant Stripping을 하면 메모리 용량과 더불어 디스크 용량도 300MB 가량 확보할 수 있는, 매우매우 훌륭하고 좋은 방법이다.
단, 단점이 있다면 적용하기가 상당히 까다롭고 위험성이 존재한다는 점이다.
Shader Variant Stripping에 대해 간단히 설명하자면 Shader에서 Material을 어떻게 보여줄 것인지 결정하는데, 이때 Keyword라는 것이 사용된다. 이 Keyword의 조합에 따라 Shader Variant 라는 게 만들어지는데, 사용되지 않는 Shader Variant들이 워낙에 많기 때문에 이걸 제거해줌으로써 최적화를 하는 방식이다.
Shader Variant Stripping을 하는 방식은 크게 2가지가 있을 것 같은데, 1번째는 "사용하지 않는 키워드가 포함된 Shader Variant들을 제거하는 방식"이다. 다만 사용하지 않는 키워드를 사용하게 되었을 때 적절히 대응해주지 않으면 Material들이 깨져보일 수 있다는 점이나, 여전히 사용하지 않는 Shader Variant들이 다수 포함될 수 있다는 점이 문제이다. 2번째는 "사용하는 Shader Variant를 제외한 Shader Variant들을 제거하는 방식"이다. 유니티 2022부터 제공하는 Strict Shader Variant Matching 기능을 사용하면 이전에 비해 다소 쉽게 적용할 수 있지만, 문제가 있다면 사용되는 Shader Variant들을 직접 수집해야 한다는 점이고, 이 과정에서 누락되는 경우 Material들이 깨져보일 수 있다는 점이다. Material이 깨지는 경우, 아예 투명하게 안 보이는 경우도 있고 마젠타 색으로 보이는 경우도 있다.
우리는 2번째 방식을 사용하는 중인데, 덕분에 Shader 용량은 90% 이상 줄어들었지만, 지금도 종종 미수집된 Shader Variant들이 발견되기도 하며, 모바일 게임이다보니 업데이트가 종종 있을 것이고, 이때마다 새로운 Shader Variant들이 추가될 가능성이 높은데, 이걸 완벽히 수집할 수 있을까? 라는 걱정이 있다.(지금은... 일례로 어떤 직업에 빛나는 구체를 날리는 스킬이 추가되었을 때, 이 구체가 Shader Variant에 영향을 준다면, 모든 맵에서 이 스킬을 사용해보지 않는 이상 모든 Shader Variant가 수집될 것이라는 보장이 없다. 업데이트가 없는 경우라면 꼼꼼한 수집 + 정기적인 업데이트 적용으로 누락된 Shader Variant들을 추가해주면 어느정도 해결이 되겠지만, 지속적으로 추가되는 경우에는 문제가 될 수 있을 것 같다. 이전에 모든 Material들을 로드해서 수집하는 방식을 사용하기도 했었는데, 이게 맵에 따라서나 주변 구조물에 따라서 등 동적으로 변경되는 경우가 상당히 많아서 완벽한 수집이 어려웠다. 만약에 나중에 처음부터 새로 개발을 할 수 있다면, 이렇게 동적으로 바뀔 수 있는 Keyword에 대해서 컨트롤할 수 있으면 좋겠다는 생각이 든다. 지금은 현실적으로 어려운 상황이지만 개발 초기부터 TA와의 긴밀한 협력을 통해 모든 multi_compile 키워드에 대해 관리를 할 수 있으면 Shader Variant Stripping을 더 안전하고 효과적으로 할 수 있지 않을까? 라는 생각이 든다.
최근에 Android SDK 버전 지원 문제로 프로젝트의 Unity 버전을 업그레이드 하였다.
(예로 2020.1 버전은 API level 30까지만 지원, 2022.3 버전은 현재 API level 35까지 지원 중)
그러면서 C# 버전 관련해서도 테스트를 하며 잠시 변경이 있었는데, nullable을 활용해서 조금 더 효율적이고 안전하게 개발할 수 있는 방법이 있는 듯 하여 정리해보기로 했다.
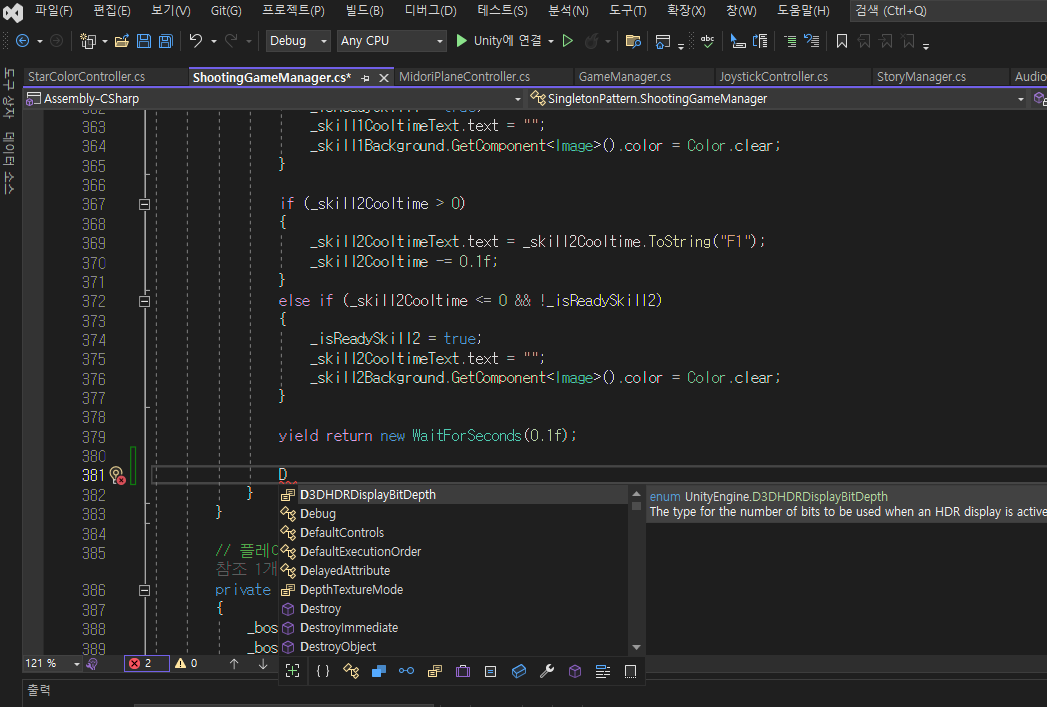
개발을 하다보면 필연적으로, 자주 만나게 되는 오류가 있는데 바로 NullReferenceException이다.
line 14와 line 27을 확인해보면, Test2함수를 실행할 때 null을 넘겨줬는데 내부에서 null 체크를 하지 않고 classA라는 객체에 접근했기 때문에 NullReferenceException이 발생한 것이다.
Test 함수에서는 classA가 null이 아닌 경우에만 classA에 접근했기 때문에 이런 문제가 발생하지 않는다.
코드를 읽어보면 NullReferenceException이 발생할 수 있다는 것을 알 수 있지만, 컴파일러가 경고를 표시해주지는 않고 있다. 때문에 실수가 발생할 여지가 있다.
개발 규모가 작다면 null을 다루는 것이 크게 어렵지 않을 수 있다. 어떤 객체가 null일지 아닌지 알기가 쉬우니까. 그러나 개발 규모가 커지고, 개발에 참여하는 인원이 많아지면 본인이 아닌 다른 사람들이 작업한 코드를 활용할 일이 많아지고, 이 경우 null 관련해서 문제가 발생할 가능성이 높아진다.
예로 몬스터의 이름을 알고 싶은데, Monster.GetName()이라는 Method가 있어서 사용했다고 치자.
monster가 null이 아니라는 걸 체크하고 사용해서 NullReferenceException이 발생하지 않을 줄 알았는데, 다른 개발자가 Monster가 죽을 때 이름이 필요없어질 거라고 생각하고 이때 name에 null을 할당해버린 사실을 몰랐다면 NullReferenceException이 발생할 수 있다.
위는 단순한 예이고, 개발을 하면서 이와 같이 null 체크와 관련해서 내적 갈등이 생기는 경우가 꽤 있다.
여기서 null 체크를 해야 하는가? 하지 않아도 되는가? 와 같은 갈등이다.
null이 올 수 있거나, 혹여나 null이 와서 크리티컬한 문제가 발생할 수 있다면 당연히 null 체크를 해줘야 하지만, 구조상 null이 오면 안 되는 곳도 있기 때문에 이런 곳에서까지 null 체크를 해줘야 하는가? 와 같은 생각을 하곤 한다.
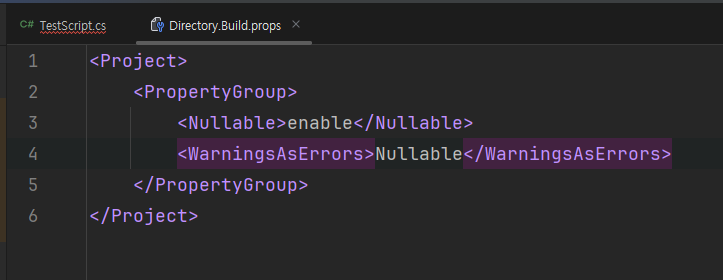
C# 8.0부터 제공하는 Nullable 기능을 사용하면 이런 고민을 크게 줄일 수 있다.
(블루 아카이브의 자동 제조 기능이 다소 아쉬운 점이 있어서 테이블 읽기도 직접 구현해보고, 자동 제조를 내가 만든다면 어떻게 만들었을까 싶어서 해보면 재밌겠다는 생각 중이다)
위와 같이 프로젝트 루트 폴더에 Directory.Build.props 라는 파일을 만들고
Unity로 개발을 하면서 텍스트를 표시할 때는 TextMeshPro를 주로 사용할 것이다.
TextMeshPro를 사용할 때는 위와 같이 ttf라고 하는 폰트 파일을 TMP(Text Mesh Pro)에서 제공하는 기능을 사용해서 SDF 에셋으로 만들어야 한다.
여기서 유심히 봐야 할 것은 아래 2가지이다.
Sampling Point Size: 글자를 Atlas에 저장할 사이즈, 클수록 글자가 선명해지지만 Atlas의 용량이 커진다.
Atlas Width & Atlas Height: 글자를 저장할 Atlas의 사이즈, 클수록 용량이 커진다.
위의 세팅을 말로 풀어쓰자면
DungGeunMo폰트의 글자를 60이라는 크기로 샘플링해서 4096x4096짜리 Atlas에 담아서 저장하겠다. 라는 의미이다.
그 결과가 이거다. 저만큼의 폰트를 쓰려고 쓸데없이 방대한 양의 Atlas를 생성해놓은 셈이다. (...)
이 16MB짜리 텍스쳐는 이유는 잘 모르겠지만 메모리에 올라가면 2배인 32MB로 올라가게 된다.
(2024/10/27 추가 - 아마 Dynamic으로 설정해놓으면 Texture에 읽고 쓰는 기능이 필요할 거라 Read/Write 옵션을 자동으로 사용하고, 때문에 CPU, GPU 양쪽 메모리에 적재되어 2배를 차지하는 것으로 추정된다.)
Atlas Width & Atlas Height를 256x256으로 줄여주면...
위와 같이 64KB짜리 텍스쳐로 줄어들게 된다.
축하한다! 당신은 16MB짜리 텍스쳐를 64KB로 줄였다. 무려 99.6%나 감소시킨 셈이다.
여기서 Sampling Point Size를 문제되지 않는 수준까지 줄이면 더 줄일 수도 있다.
(*추가: 단, 주의해야 할 점은 dynamic 폰트를 사용한다면 플레이 중에 새로운 글자를 보여주는 경우 이 텍스쳐에 글자들이 새로 추가된다는 점이다. 그러면 텍스쳐가 여러 장으로 분리되고 각 글자마다 참조하는 텍스쳐가 다른 경우 드로우콜이 늘어날 수 있기 때문에 해당 폰트에 사용될 글자수를 예측하여 적절한 크기로 할당하여 균형을 잡는 것이 중요하다.)
줄인 이후 asset 용량이 32,831KB -> 146KB로 줄어든 것도 확인할 수 있다.
Atlas Population Mode를 Dynamic으로 설정하고, Multi Atlas Textures에 체크한 다음 Atlas의 사이즈를 줄여서 사이즈를 더 줄일 수도 있지만, 이 경우 드로우콜이 늘어나고 오버헤드가 발생할 수 있어 최대 2개 정도로만 쪼개지도록 해놨다. (용량이 큰 폰트만)
내가 읽은 설명 상으로는 Dynamic으로 해놓으면 글자를 사용하기 전까지는 Atlas에 그려지지 않는 것으로 알고 있는데, 실제로 메모리를 찍어보니 처음부터 전체 텍스쳐가 한꺼번에 메모리에 올라가 있는 것을 확인할 수 있었다.
* Dynamic은 사전에 미리 Character Table에 등록해놓지 않은 경우에도 ttf에서 실시간으로 글자를 불러와서 Atlas에 추가하는 식으로 작동되는 것 같다. (이 때문에 에디터에서 플레이를 하고 저장하면 Font Asset에 계속 변경사항이 생기는 문제가 있었다.) 아예 비워놓는 게 메모리 측면에서는 가장 이득이겠지만, 그러면 모든 글자에 대해 동적인 로딩이 발생할 테니 자주 사용하는 글자 정도는 추가해두는 게 성능과도 타협을 볼 수 있는 방법일 것 같다.
* 드로우콜을 줄이기 위해서라도 지속적으로 UI에 나타나는 글자들은 같은 Atlas에 담는 것이 좋을 것 같다. 이를 위해서는 직접 글자들을 수집해서 저장할 수도 있겠고, 아예 비워놓으면 플레이하면서 알아서 첫 Atlas에 저장될 것 같다. (때문에 Atlas 크기를 너무 작지 않게 하는 것이 좋겠다.) 이전에 한글 XXXX자를 미리 생성해서 넣어놓는 방식을 사용하기도 했었는데, 확인해보니 실제로 사용되지 않는 글자들이 많을 뿐더러 Dynamic으로 글자를 가져오는 게 그렇게 느리지도 않은 것 같다. 효율적인 메모리 관리와 배칭을 위해서 Dynamic을 사용해야 하는 경우, Atlas에 최소한의 ASCII 문자들만 넣어놓는 것도 좋은 선택일 것 같다.
============================================
2. 폰트 중복 제거하기
메모리 프로파일러로 찍어서 확인을 해보면 위와 같이 같은 폰트의 Atlas가 중복으로 메모리에 올라가 있는 모습을 확인하게 될 수도 있다.
이 문제는 몇 가지 경우로 나뉜다.
1. 에셋 번들을 빌드할 때 Addressables를 사용하는 중인가?
-> (아마도 내가 아는 선에서는) 폰트 중복 문제를 완벽하게 해결할 수 있을 것이다. 폰트를 앱 빌드할 때 포함되도록 하면 해결된다고 알고 있다.
2. 에셋 번들을 빌드할 때 Scriptable Build Pipeline이 아닌 기본 AssetBundle의 Pipeline을 사용하는 중인가?
-> 이전에 언급했던, 번들을 다른 옵션으로 빌드하기 위해 분리해서 빌드하는 경우 Dependencies가 제대로 참조되지 않아서 폰트가 중복될 수 있다.
예시)
폰트 데이터가 포함된 Font 번들을 LZ4 형식으로 압축하여 빌드
해당 폰트를 사용하는 A, B, C 번들을 LZMA 형식으로 압축하여 빌드
Scriptable Build Pipeline으로 빌드하는 경우 한꺼번에 빌드가 되어서 A -> Font / B -> Font / C -> Font 각각 번들을 잘 참조하지만, 기본 AssetBundle의 Pipeline을 사용하는 경우 Font 번들과 A, B, C 번들이 따로 빌드되기 때문에 (Font) / A(A + Font) / B(B + Font) / C(C + Font) 로 각각 나뉘어 빌드된다.
이 경우, Font 번들이 로드된 상태에서 A 번들을 로드하면, A 번들을 로드하면 A 번들은 A 번들을 빌드할 때 포함된 Font 데이터를 참조한다. A 번들 내에 들어있는 Font 데이터는 Font 번들에 있는 Font 데이터와는 별개로 인식되기 때문에 메모리에 중복으로 적재된다. B / C 번들을 로드할 때도 동일한 현상이 발생해서 이 경우 최대 4개의 폰트 데이터 중복 적재가 일어나게 된다.
특히나 폰트에 Fallback을 사용해서 32MB짜리 폰트 3개를 묶어서 사용 중이라면 순식간에 300MB에 달하는 메모리 내 중복이 발생하는 것이다.
3. Addressables 외에 Scriptable Build Pipeline 혹은 AssetBundle의 Pipeline을 사용하는 중인가?
-> 이 경우 AssetBundle에 포함되는 폰트와, 앱 빌드 시 포함되는 폰트를 하나로 합칠 수 없기 때문에 강제로 분리하여 사용하게 된다. 게임을 시작할 때 AssetBundle을 받기 전 텍스트를 보여줘야 할 텐데, 이때 보여주는 폰트는 앱 빌드 시 포함되는 폰트이고, 이후 AssetBundle에서 로드하여 보여주는 폰트는 AssetBundle에 포함된 폰트라 서로 다른 폰트이다. 폰트 데이터는 씬을 넘어가야 사라지는 것으로 추정되니 AssetBundle에 포함된 폰트를 보여주는 경우 맨 처음 씬과 분리해야 폰트 중복을 막을 수 있을 것이다.
============================================
[주의해야 할 점]
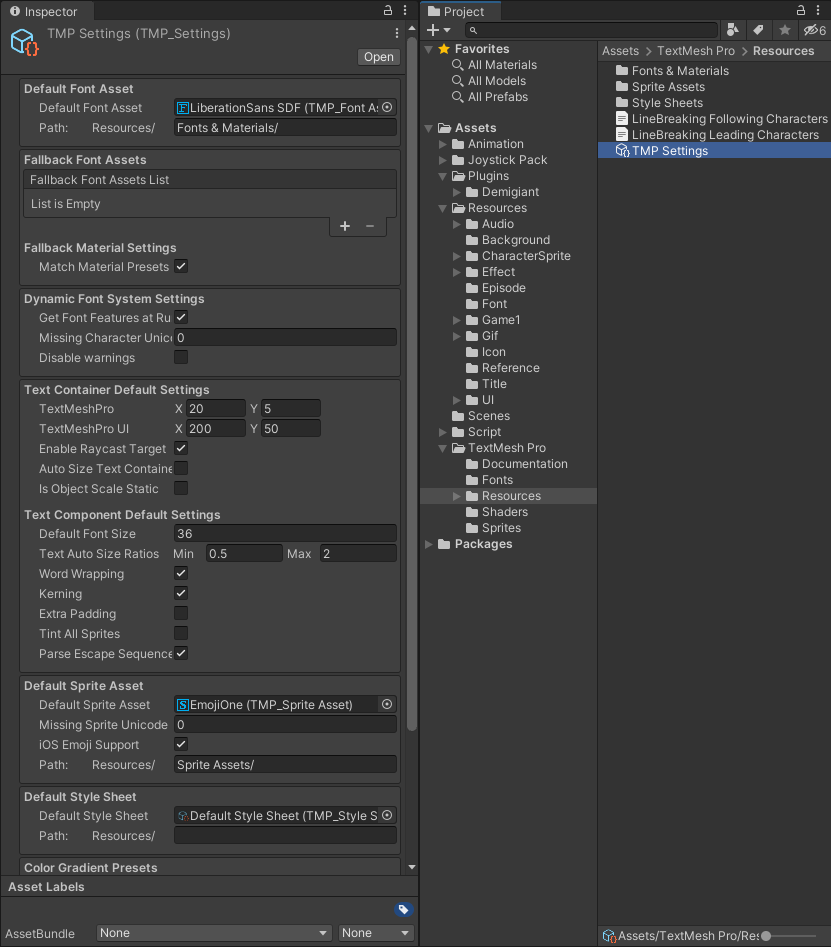
1. TMP Settings를 사용하는 경우 Fallback으로 등록되는 듯 하니 주의하자.
TMP Settings라는 Asset이 존재한다. Default Font Asset은 기본적으로 어떤 폰트를 사용할 것이냐?에 해당하는 부분인데, 문제는 얘가 모든 폰트에 대해 Fallback으로 지정되는 것으로 추정된다는 점이다.
즉, 얘를 앱 빌드할 때 포함시킨다면...
Default Font Asset에 들어간 폰트가 앱 빌드에 포함되고, 모든 폰트에 대해서 Fallback으로 지정되기 때문에 에셋 번들에 포함된 폰트만 사용하더라도 항상 앱 빌드에 포함된 폰트가 메모리에 같이 적재되는 현상이 발생한다.
이걸 피하기 위해서 Default Font Asset과 Fallback을 지워준 후에 Default Font Asset에 해당하는 폰트들을 각각의 폰트의 Fallback으로 달아주었는데, 지금 생각해보니 TMP Settings를 에셋 번들에 포함시키면 될 것 같기도 하다. (이렇게 해도 앱 빌드에 포함되지 않는다는 전제 하에. 이거는 테스트를 해 봐야 할 것 같다.)
=> 이 방법은 유효하지 않았다. 아마 TMP Settings가 필수적으로 저 위치에 포함되어야 하고, 무조건 앱 빌드에 포함되었던 것으로 기억함. (이것까진 확실하지 않음)
2. AssetBundle과 Resources 폴더의 폰트 배치에 주의하자.
2-1. Resources 폴더에만 폰트를 넣고 AssetBundle을 빌드하는 경우
먼저 Resources 폴더에 있기 때문에 앱을 빌드할 때 포함된다. 그리고 AssetBundle를 빌드할 때도 Resources 폴더의 폰트를 함께 빌드한다. 얘네는 정확히 어떤 식으로 Dependencies가 지정될지 확인은 안 해봤지만, AssetBundle에 명시적으로 포함하는 것이 좋을 것으로 추정된다.
2-2. AssetBundle에만 폰트를 넣지만, 빌드에 포함되는 씬에서 해당 폰트를 사용하는 경우
AssetBundle에 폰트가 정상적으로 포함되고, 앱 빌드에도 폰트가 들어간다.
2-3. AssetBundle과 Resources 폴더에 동일한 폰트를 각각 넣는 경우
특정 경우에 문제가 발생할 수 있다.
예를 들어서...
1. AssetBundle에서 폰트 A, B, C, D를 사용하고 있다.
2. A의 Fallback으로 B, C, D가 등록되어 있다.
3. 빌드에 포함된 씬에서 폰트 A를 사용하고 있으니 Fallback 폰트인 B, C, D를 Resources 폴더에 따로 넣어준다.
위의 경우에 문제가 발생할 수 있다.
이미 에셋 번들에 포함된 A를 앱 빌드할 때 포함시키면서 Fallback 폰트인 B, C, D도 같이 앱 빌드에 포함된다.
그리고 Resources 폴더에 들어있는 B, C, D는 별개의 폰트이기 때문에 앱 빌드에 별도로 포함해서 빌드한다.
즉, 폰트 A를 사용하면서 Fallback으로 사용되는 B, C, D는 AssetBundle 폴더에 들어있는 B, C, D이고, Resources 폴더에 넣어준 B, C, D는 실제로는 사용하지 않으면서 앱 빌드에만 포함되는 셈이다. 이 경우 메모리에는 적재되지 않겠지만, apk 빌드 사이즈가 커질 수 있으니 조심해야 한다.
이외에도 SDF를 만들 때 필요한 글자만 지정해서 만들 수 있는데, AssetBundle을 받기 전에 보여주는 글자는 어느 정도 정해져 있으니까 해당 글자만 담아서 따로 폰트를 만드는 방식으로 apk빌드 파일을 줄이는 방법도 있을 것이다.
JetBrains Rider는 JetBrains사에서 개발한 IDE이다. Visual Studio와 비슷하다고 생각하면 된다.
이전부터 관심은 있었는데 얼마 전에 직장 동료가 할인 소식을 알려줘서 다행히도 저렴한 가격에 구입할 수 있었고, 약 1주+@간 이용해본 소감은... 돈이 아깝지 않을 정도로 굉장히 만족스럽게 사용하고 있다.
그래서 이번 주 스터디는 Rider를 잘 써보자는 차원에서 Rider의 장점이나 활용법 등을 준비해갔고, 지금 쓰는 글도 약간 이 내용을 다듬어서 Rider의 장점을 정리하고, 효율적인 개발을 할 수 있도록 권장해보고자 한다.
IDE(통합 개발 환경) : 코딩, 디버그, 컴파일, 배포 등 프로그램 개발에 관련된 모든 작업을 하나의 프로그램 안에서 처리하는 환경을 제공하는 소프트웨어
IDLE
Visual Studio
Dev-C++
Eclipse
PyCharm
Jupyter Notebook
Android Studio
Visual Studio Code
Rider
…
IDE에는 다양한 종류가 있는데, 내가 사용해본 IDE는 위와 같다. 대략적으로 서술한 순서대로 사용했던 것 같다. Python의 IDLE은 고등학교 정보 시간에, 그 밑으로는 대학교 때, Visual Studio Code는 이전 직장에서 TypeScript를 사용하면서, 마지막으로 Rider는 현 직장에서 사용해보게 되었다.
JetBrains사에서 제시하는 Rider의 장점들과, 그에 해당한다고 생각하는 내용에 대해서 정리해보겠다.
원래 자료는 회사에서 짰던 코드로 만들어서 이전에 내가 만들었던 코드를 열어서 살펴보면서 자료를 만들도록 하겠다. 굉장히 냄새나는 코드들이 많을 것으로 예상한다. ㅋㅋ.
탁월한 코드 분석
Rider는 오류 및 코드 스멜을 탐지하도록 도와주는 2200여 개의 실시간 코드 검사 기능을 자랑합니다. 1000개가 넘는 빠른 수정 기능도 제공되어 탐지된 문제를 개별적으로 또는 일괄적으로 해결합니다. 그저 Alt+Enter를 눌러 하나를 선택하기만 하면 됩니다. 프로젝트 내 오류를 전체적으로 보려면 솔루션 전체 오류 분석(SWEA)을 사용하세요. 이 도구는 코드 베이스의 오류를 모니터링하여 문제가 생겼을 때 텍스트 에디터에 문제 파일이 열려 있지 않아도 알려줍니다.
코드 가독성 향상 (예시)
음... 똥스멜이 나는 코드다. Rider가 switch로 바꿀 수 있다고 추천해준다. 참고로 초록색 점선은 바꿔도 되고, 안 바꿔도 된다는 뜻이다.
Alt+Enter, Enter를 입력하면...?
Rider가 향기나도록 바꿔준다. 음~
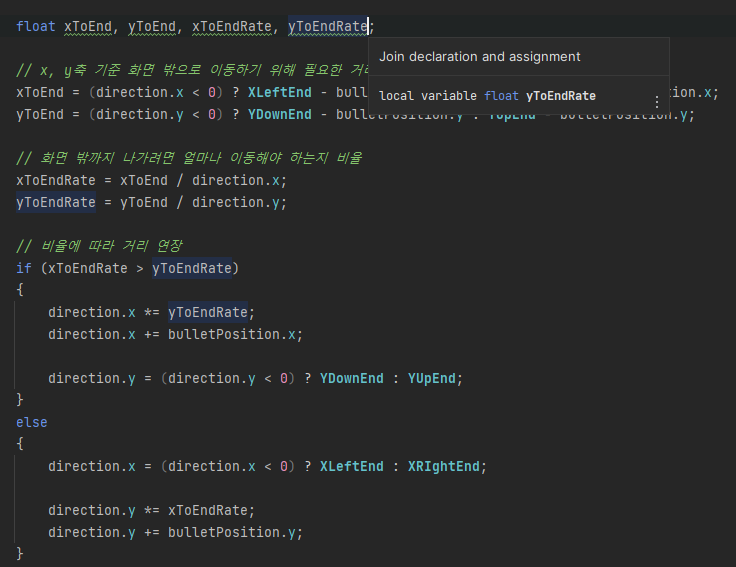
이 경우는 미리 선언할 필요가 없다.
쓸 때 바로 선언할 수 있도록 바꿔준다.
변수명/함수명 교정 (예시)
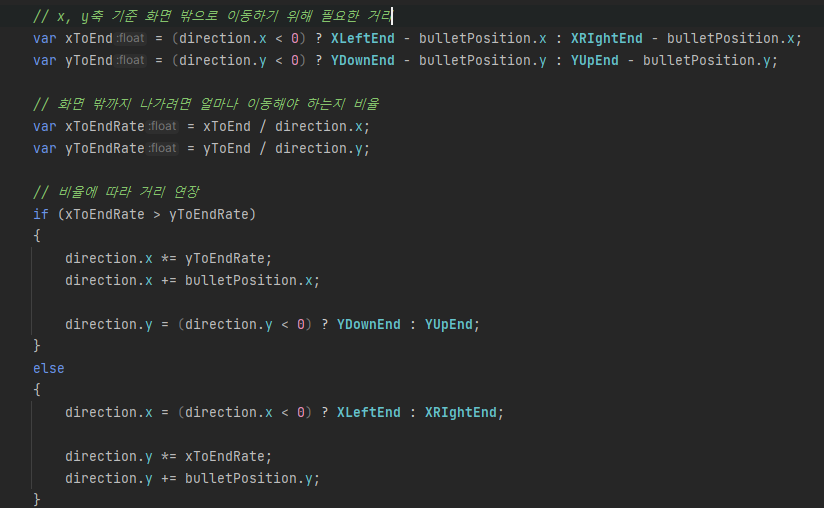
이름은 대체로 맞춰서 짓긴 했는데, 미처 발견 못한 오타가 있었다. XRightEnd를 XRIghtEnd라고 적었던 모양이다.
규칙에 어긋나는 경우에는 저렇게 초록색으로 밑줄을 그어준다. 가끔 노란색으로 그어주는 경우도 있는데 차이는 잘 모르겠다. 내부에서 판단하기를 "이거는 문제 없는 것일 수도?" 라고 생각하면 초록색, "이건 명백히 잘못됐다" 하면 노란색으로 그어주는 것 같다.
참고로, 원하는 코드 스타일을 설정에 저장해놓고 내 입맛에 맞는 코드를 작성할 수도 있다.
대충 이런 느낌이다. C#에서는 지역 변수는 _로 시작하는 것이 보편적이기 때문에 수정하라고 밑줄을 그어준다.
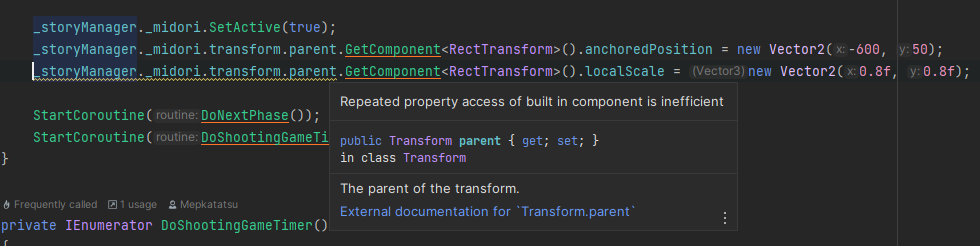
비효율적인 코드 수정 (예시)
위의 경우는 같은 컴포넌트에 연속적으로 접근하기 때문에 캐싱해놓고 쓰는 것이 효율이 좋다.
Rider의 조언을 받아들이면 코드가 이렇게 변한다. 효율도 좋아지고 코드도 조금 더 보기 깔끔해졌다.
유니티에 대한 지식도 있어서 이런식으로 Tag를 직접적으로 비교하는 것보다는 CompareTag를 사용하라고 권장해준다. 아마 내 기억에 gameObject.tag는 string을 하나 만들어 반환하면서 가비지를 생성하는 것으로 알고 있다.
무거운 함수 표시
또, Rider는 주황색 밑줄로 무거운 함수를 표시해준다.
지금은 위 코드가 처음 1번만 실행되는 함수라 신경을 쓰지 않아도 괜찮지만, 예를 들어서 위 코드가 update문에서 돌아가고 있는 코드라면?
매 번 GetComponent를 하는 것보다는 Awake에서 1번만 캐싱해놓고 재활용을 하는 것이 성능상 이점이 클 것이다.
이런식으로, 무거운 함수를 따로 표시해주기 때문에 코드를 짤 때 한 번 더 효율에 대해 고민해볼 수 있게 해준다.
private으로 전환 가능한 것들을 알려줌
public으로 되어있지만, 내부에서만 사용된 코드들은 private으로 전환할 수 있기 때문에 전환 가능하다는 것을 알려준다. 주로 이전에 public으로 만들어서 밖에서 쓰고 있었다가, 다른 함수를 통해 부르는 등의 경우에 이렇게 되는데, private으로 선언해서 해당 함수로만 접근 가능하도록 변환해주면 헷갈릴 여지가 적을 것이다.
자동 완성이 똑똑함
이전에 내내 Visual Studio에서 작업했는데도 불구하고 Visual Studio는 이상한 함수를 추천해준다. 특히나 유니티의, 잘 쓰이지 않는 함수를 뜬금없이 추천하곤 해서 약간 불편하다.
같은 지점에서 동일한 문제를 쳐보면, 완전히 다른 결과가 나온다.
Rider는 지역 함수/최근에 선언한 함수/사용한 것 위주로 추천해주는 느낌이다. 때문에 코드 작성이 훨씬 편해진다.
+듣기로는 이번에 사용할 변수도 예측해서 자동완성을 해준다고 한다.
탐색 및 검색
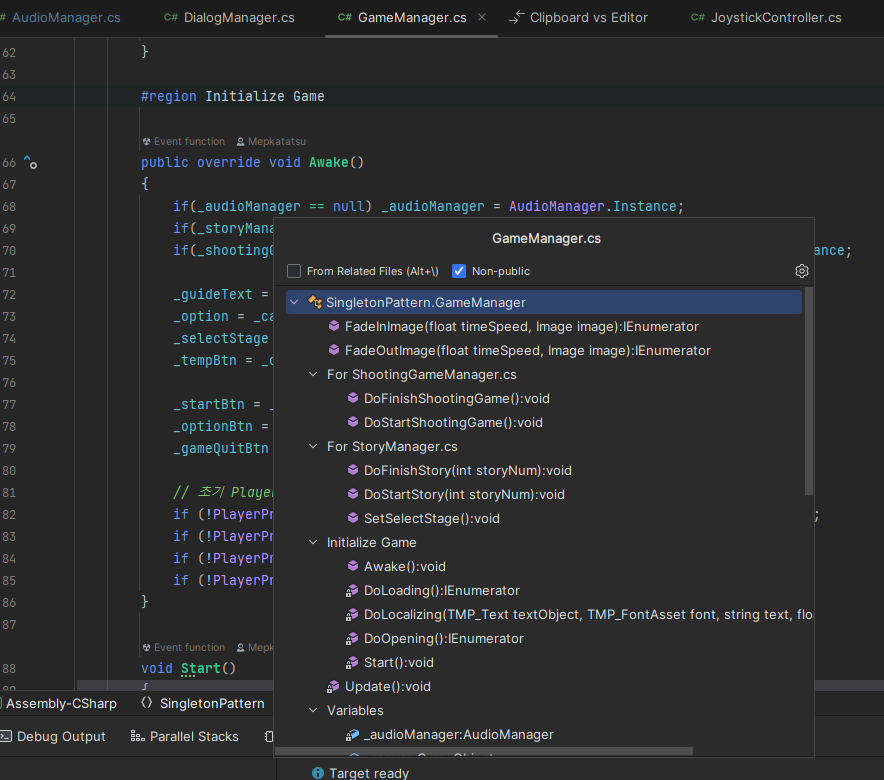
파일, 유형 또는 코드 내 멤버 어디로든 이동하고 설정 및 액션을 검색하세요. 일반 Search Everywhere(전체 검색) 단축키로 모두 수행할 수 있습니다. 여러 언어 또는 문자열 리터럴에서의 사용 위치를 포함해 어떤 심볼의 사용 위치든 검색할 수 있습니다. 컨텍스트 탐색의 경우, Navigate To(다음으로 이동) 단축키 하나로 심볼에서 해당 심볼의 베이스 및 파생 심볼, 확장 메서드, 구현으로 이동할 수 있습니다.
Getter와 Setter가 구분된다.
위와 같이 Visual Studio에서는 "모든 참조 보기"를 누르면 getter와 setter의 구분이 없이 보여준다.
rider에서는 이런 식으로 보이는데, 초록색으로 나가는 모양이 Getter로써 사용된 부분이다.
왼쪽의 초록색 부분을 눌러 Getter 부분을 끄면, Setter로 사용된 부분만 볼 수 있다.
위 예시는 구분하기 쉬운 경우라서 크게 대단해보이지 않는데, 정말 여기저기 쓰인 변수의 Set 부분이 어딘지 찾으려고 눈이 빠지게 쳐다보는 경우가 아주 가끔 있는데, 이 기능이 있으면 그렇게 목빠지게 쳐다볼 이유가 없다!
상속 받은 것만 따로 볼 수 있음
Visual Studio에서는 Class의 참조를 보면 상속된 경우와 사용된 경우가 같이 보인다.
Rider에서는 상속된 경우만 따로 나타나서 보기가 더 편하다.
위 경우는 상속만 되고 사용된 경우가 없어서 별 차이 없어보이지만, 약 100군데에 사용되었고 그중 약 10군데에 상속되었다고 하면 훨씬 보기가 편하다.
Git 변경 내역을 통해 누가 작성한 코드인지 바로 알 수 있음
빨간색으로 동그라미를 친 부분을 누르면 깃 수정 내역을 바로 왼쪽에서 볼 수 있다.
혼자 작업하는 경우는 상관없지만, 공동 작업을 하다보면 도움이 많이 되는 기능이다.
"누가 작성한 코드지?" (물어보려고)
"아씨... 누가 작성한 코드지?" (원망하려고)
두 경우에 Git을 뒤져볼 필요 없이 바로 누가 작성한 코드인지 알 수 있으니 시간도 많이 절약된다!
언제 수정된 것인지도 알 수 있는데, 이 시기를 금방 알 수 있는 것도 코드 이해에 도움이 되는 경우가 있다.
참고로, 해당 내용은 브랜치에서 머지해온 경우 머지한 사람의 이름이 나오기 때문에 오해의 소지가 있을 수도 있다.
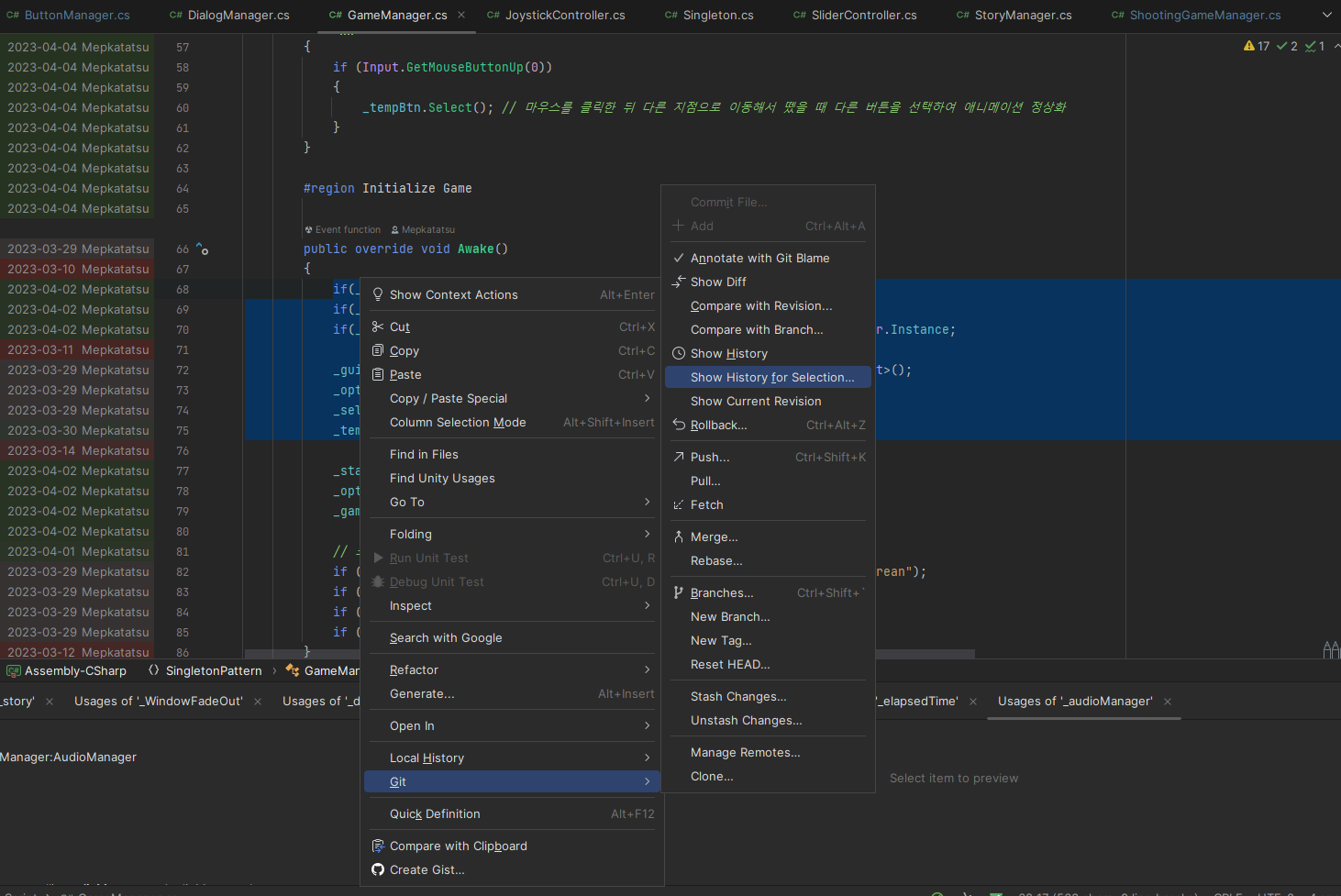
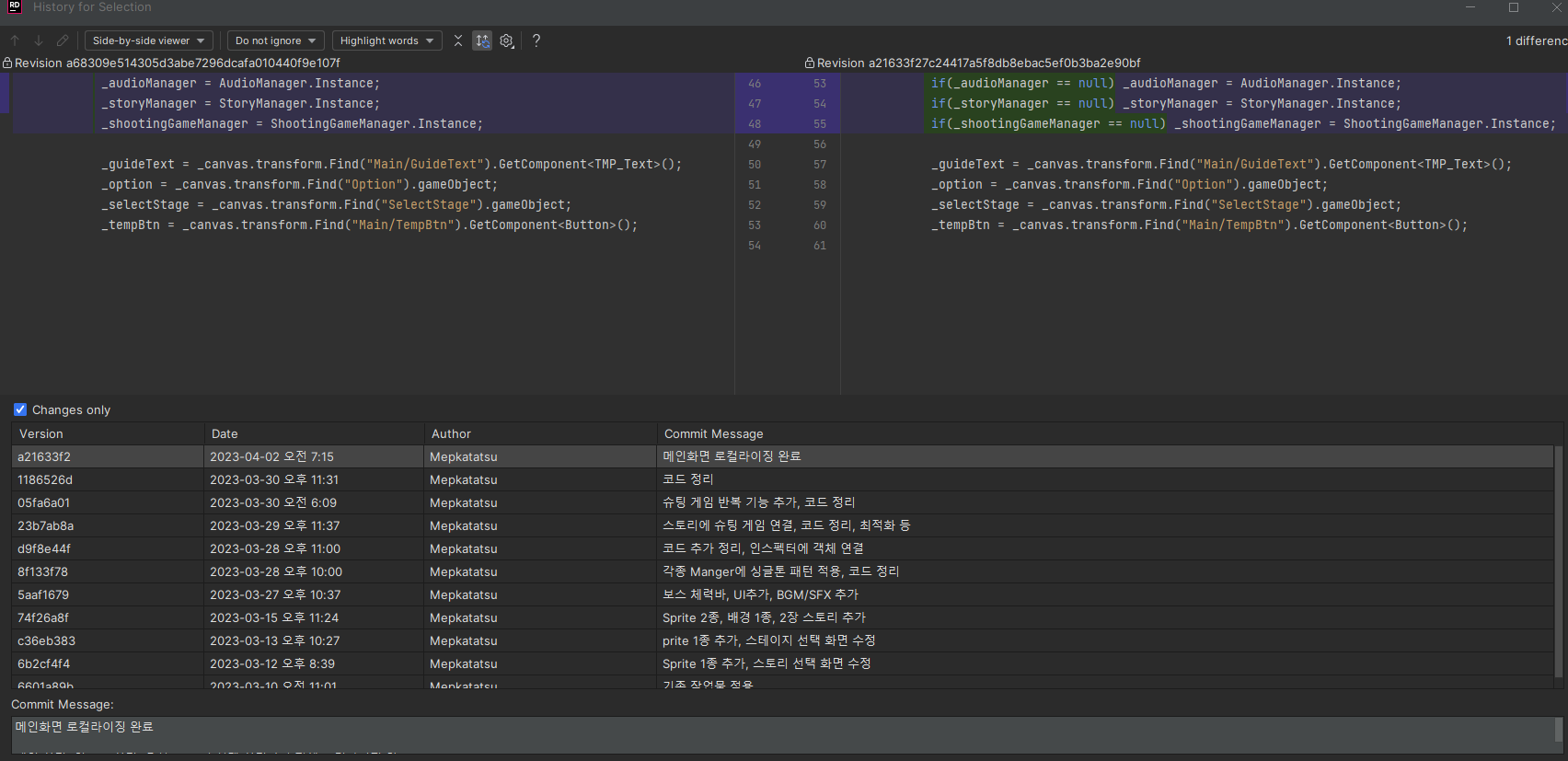
좀 더 자세히 보고 싶다면 원하는 영역을 드래그하고, 우클릭 -> Git -> Show History for Selection 으로 변경 내역을 볼 수있다.
이렇게 커밋 내역과 누가 작성한 것인지, 무엇이 바뀌었는지 바로 나타나서 엄청나게 편리한 기능이다.
깃 내역을 지금 다시보니 짧은 구간이지만 뭔가 예전에 열심히 했던 것 같아서 괜히 기분이 좋다. ㅎㅎ.
TODO
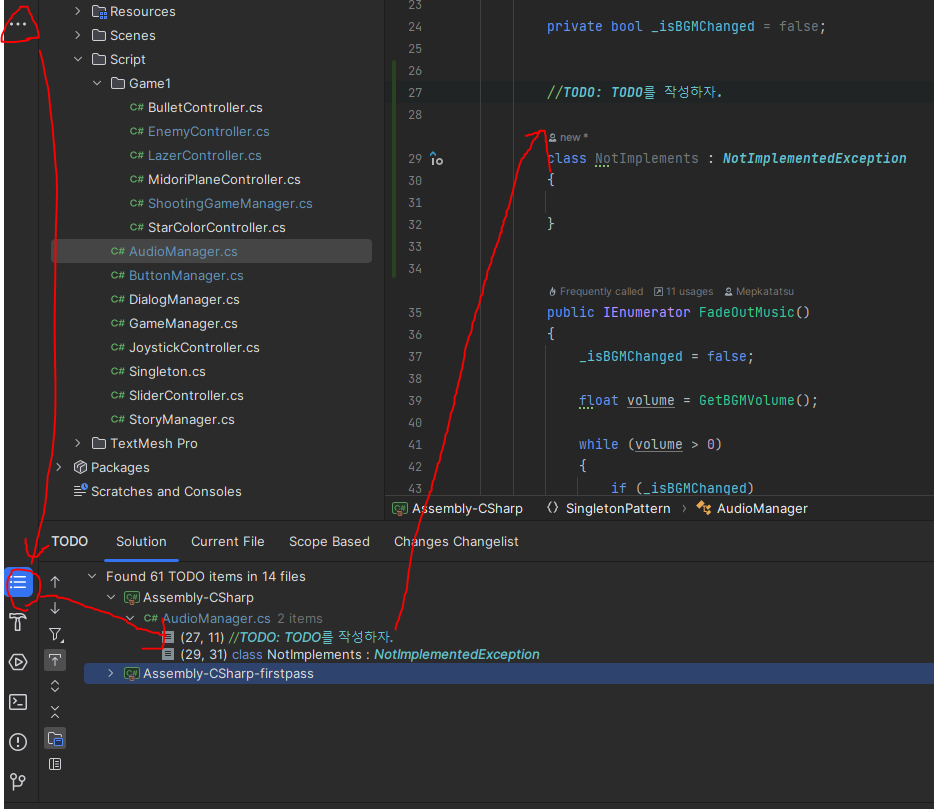
TODO를 모아서 볼 수 있다.
Visual Studio도 TODO를 모아서 보는 기능은 있다지만 접근성이 안 좋아서 그런지 한 번도 써본 적이 없는데, Rider는 상당히 간편하다. 추가로 NotImplementedException 등과 같이 Rider가 판단한 TODO도 기록된다.
원래는 상속받아서 구현할 함수를 구현 안하고 기본으로 넣으면 저게 들어가는데 이때 상속을 아예 안써서 넣을 게 없어서 저렇게 했다. -_-;;
Unity 관련 기능
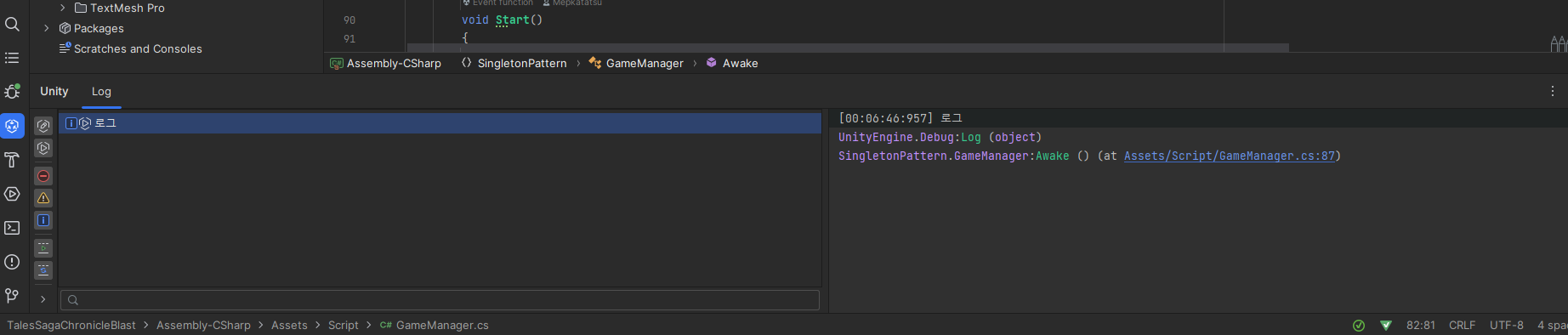
Unity 로그가 표시됨
라이더랑 유니티 에디터 연결만 해주면 Unity 로그가 Rider에도 나타나며 원하는 호출 스택으로 간편하게 바로 이동할 수 있다.
에디터에서 실수로 재시작해서 날아갔어도 Rider에서 따로 날리지 않으면 안 날아가서 다시 볼 수 있어서 굳이 Editor.log 찾아가서 뒤지는 것보다 더 편리하다.
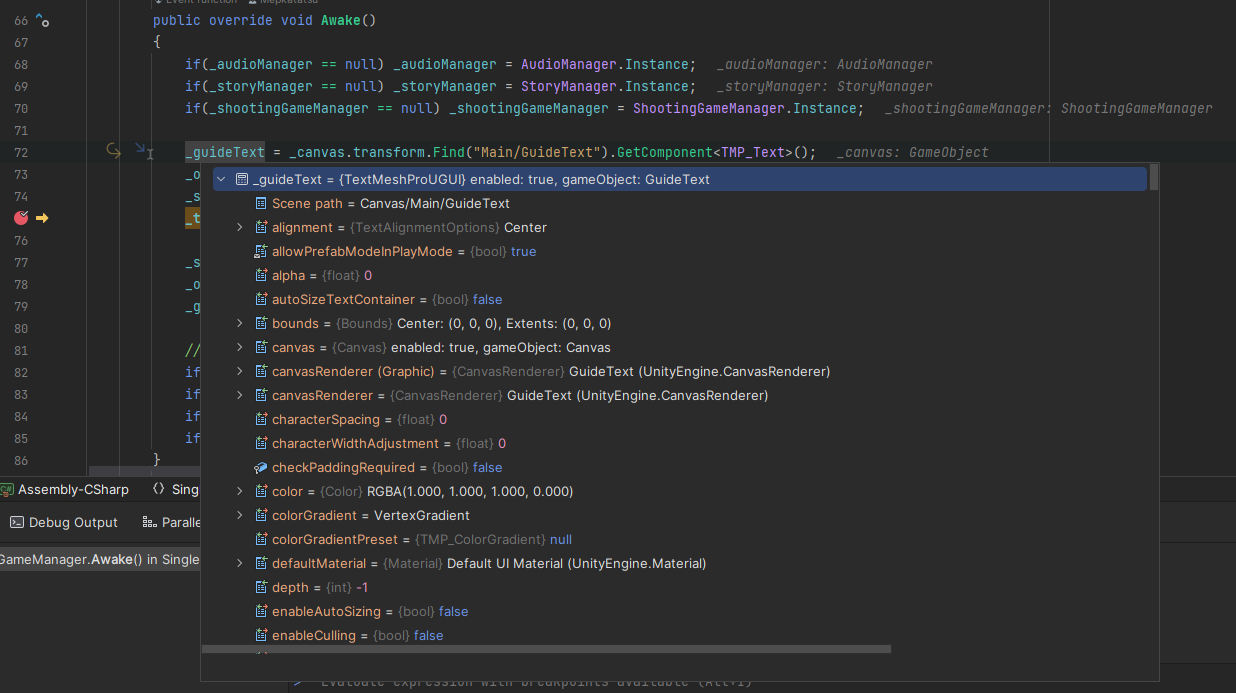
Unity Editor 관련 정보가 뜸
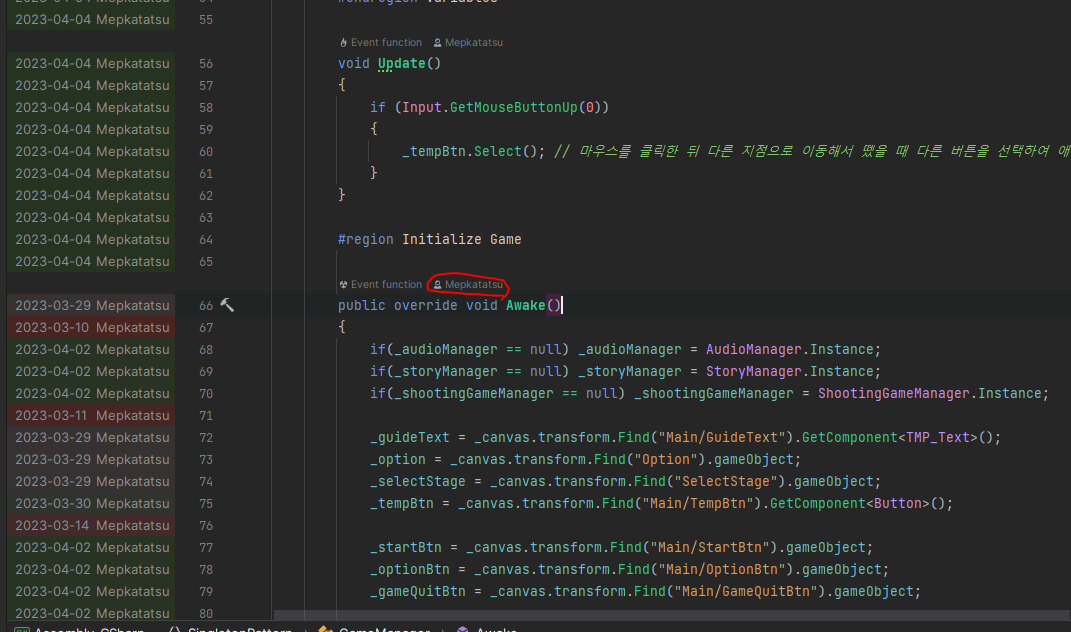
디버그할 때 현재 씬의 어떤 오브젝트에 붙어있는지 경로를 상세히 알려준다. (사진에서 보이는 Canvas/Main/GuideText)
이외에 해당 Component의 정보들도 상세히 알려준다.
상단에서 Unity Editor 실행을 제어할 수 있음
상단에서 실행/일시 정지 등을 제어할 수 있다.
+유니티 에디터에 디버깅 연결하고 끊을 때 Visual Studio를 사용할 때보다 훨씬 빠르다.
Visual Studio의 경우 보통 빨라도 10초 이상 걸리고, 끊거나 할 때도 멈추는 등의 문제가 있는데 라이더는 5초정도면 빠릿빠릿하게 붙고 떨어지는 것 같다. 여태 멈춘 적도 없어서 디버깅도 굉장히 빨라졌다.
디버깅
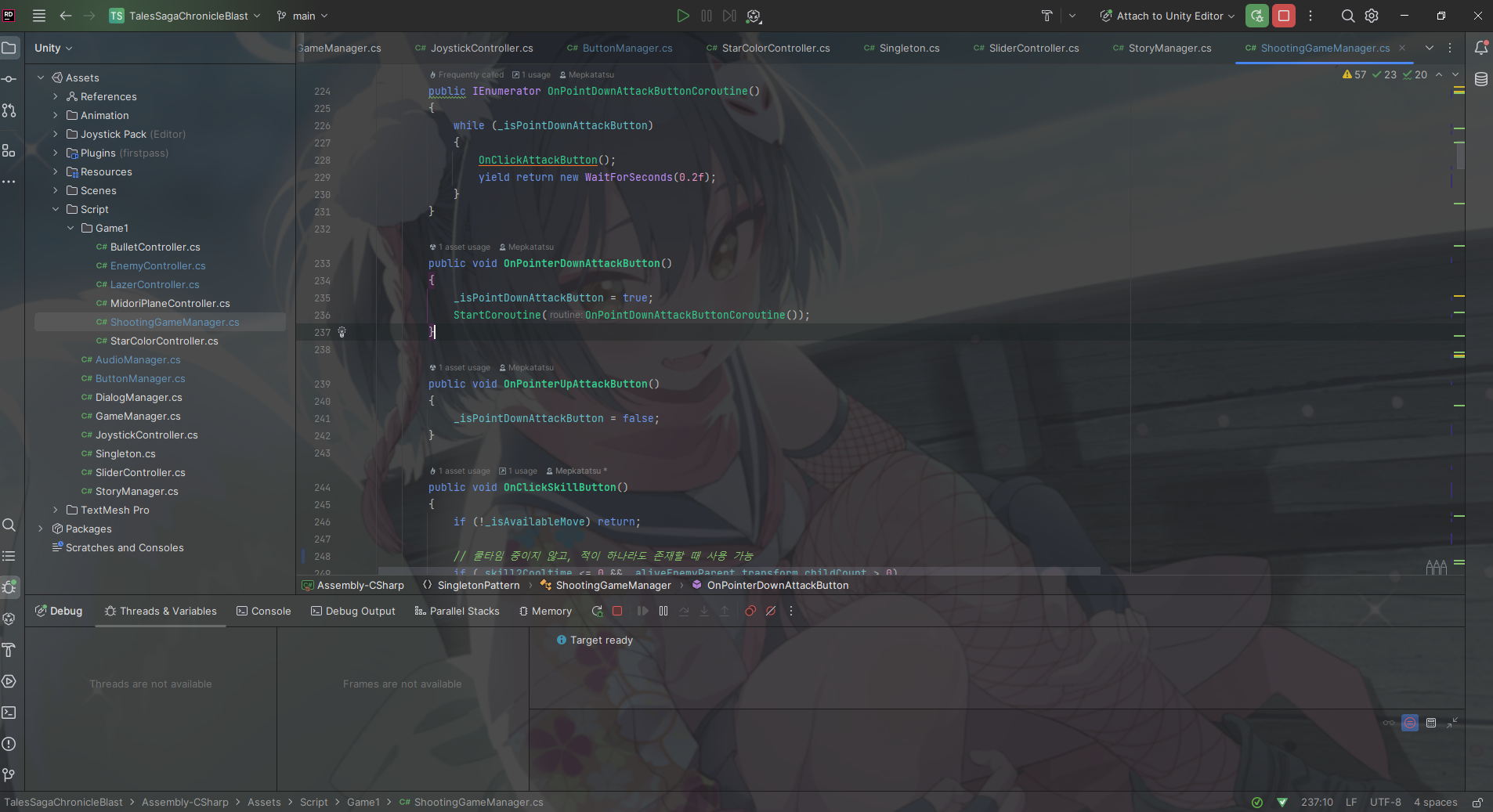
중단점에 조건거는 것이 간편함
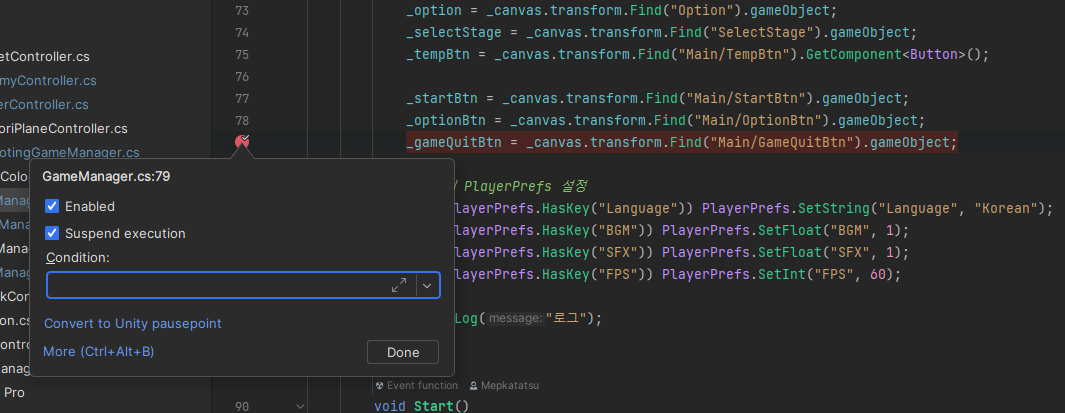
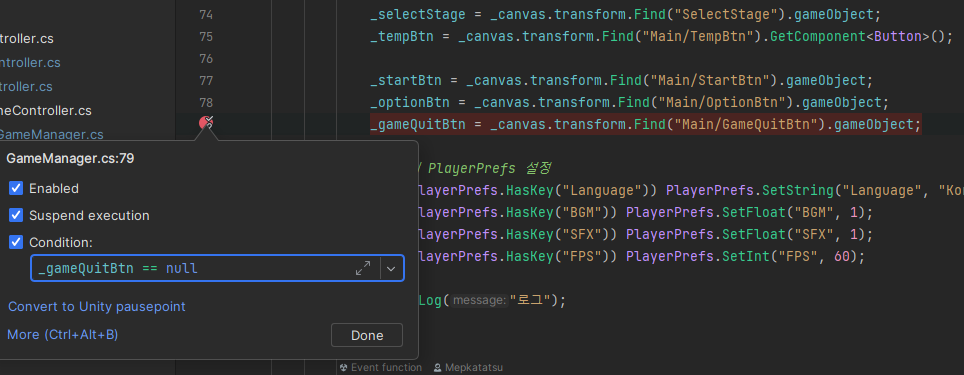
중단점을 걸고 우클릭을 하면 Condition에서 바로 조건을 걸 수 있다.
Visual Studio에서도 있는 기능인 것으로 아는데 쓰기가 불편해서 잘 사용하지 않았는데, Rider에서는 굉장히 간편하게 쓸 수 있다. 또, 인텔리센스의 도움을 받아 자동 완성도 가능하다.
이런 식으로 조건을 걸 수 있다. 위 경우에는, _gameQuitBtn == null 인 경우에만 멈추라는 의미이다.
*** 다만, 조심해야 하는 점은, 조건에 함수도 넣을 수 있지만 여기서 사용하는 함수가 값을 바꿔버리면 예상치 못한 문제가 발생할 수 있다. ***
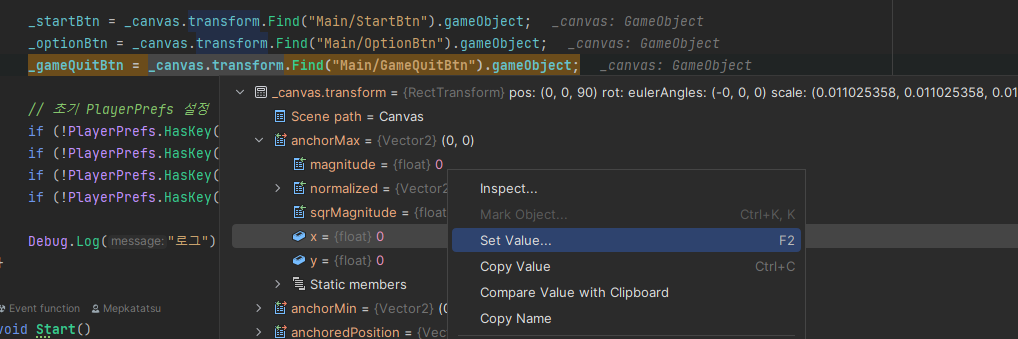
디버그를 하면서 값을 변경할 수 있음
디버그를 하면서 Set Value로 원하는 값을 변경할 수 있다.
다만, 몇 가지 제한이 있고 잘못 넣으면 오류가 생기니 조심해서 사용해야 할 듯.
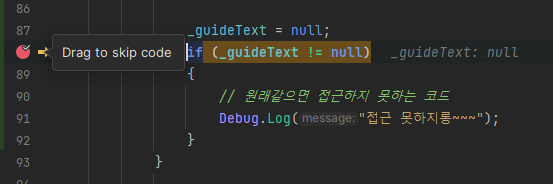
디버그를 하면서 중단점에서 코드 이동이 상대적으로 자유로움
중단점 옆의 화살표를 드래그해서 코드 진행 상황을 이동할 수 있다.
Visual Studio에서도 가능하다는 것 같기는 한데, Rider에서 더 자유롭다고 한다.
원래 아래를 진행중이었는데, 위로 돌아간 모습이다. 아래로도 이동이 가능하다.
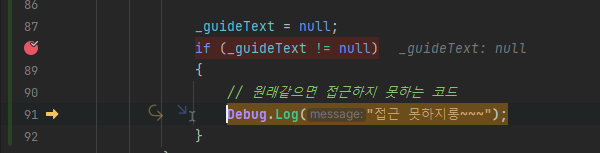
추가로, 위 코드는 원래같으면 접근하지 못하는 코드다.
_guideText = null을 선언한 직후이기에 null이라 조건문에서 걸릴 것이다.
하지만 이런 식으로 끌어서 강제로 접근시킬 수도 있다.
단, 왔다갔다 하면서 값이 바뀌거나 예상치 못한 문제들이 생길 수 있으니 주의하자.
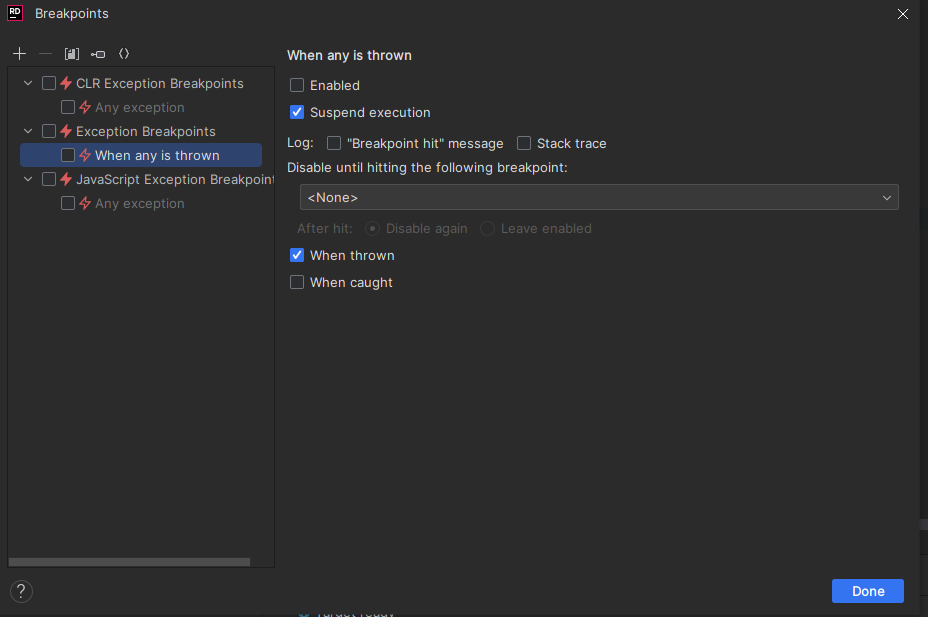
Try Catch에서 Catch가 발생했을 때 바로 Catch로 가지 않고 Exception이 발생한 부분 표시
Ctrl + Alt + B를 누르면 위와 같은 창이 뜨는데, CLR Exception Breakpoints 쪽인지, Exception Breakpoints 쪽인지 정확히는 모르겠지만 Enabled를 체크해주면 try-catch문에서 Exception이 발생했을 때 바로 catch로 넘어가지 않고 Exception이 발생한 부분을 표시해준다고 한다. 뭐... 둘 다 체크해도 괜찮을 듯?
이외에도...
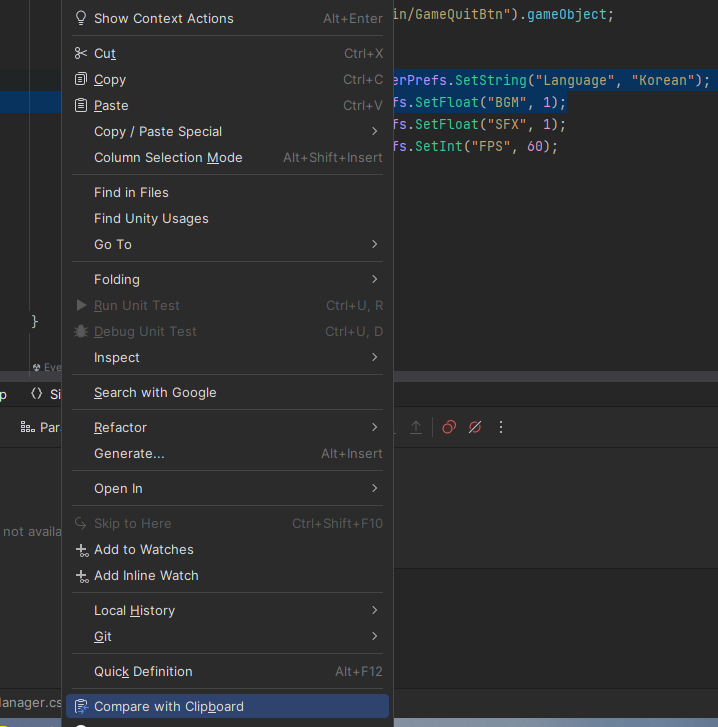
클립보드에 복사한 것과 선택한 영역을 비교하는 기능
두 개가 비슷한 경우 어떤 값이 다른지 눈에 띄게 확인할 수 있다.
Alt + \ 로 멤버 변수/함수에 빠르게 접근이 가능함
이것도 Visual Studio에 있던 기능인 것 같기는 한데... 나름 편리한 기능인 것 같다.
이전 글에서 Addressables에 대한 내용을 다루었었는데, 메모리 관리와 관련해서 추가로 찾은 내용이 있어서 올리고자 한다.
Addressables은 자체적으로 Reference Count를 관리하여 AssetBundle 내의 모든 Asset이 Release되면 AssetBundle을 통째로 자동으로 메모리에서 해제해준다는 내용을 찾아볼 수 있었다.
또, 마찬가지로 AssetBundle끼리도 Reference Count를 가지고 있는 것으로 보였다.
하지만, 각 Asset에 대한 Reference Count는 어떻게 관리를 하는지에 대해서는 찾아보기가 조금 어려웠다.
만약 각각 Asset을 직접 해제해줘야 한다면 작업이 상당히 번거로워질 것이기 때문에, 이점이 크지 않을 것 같았다.
InstantiateAsync와 Release에 대한 개념은 인지하고 있었기 때문에 과연 이 기능이 Asset 내부에서도 Reference Count를 관리해주며 자동으로 메모리를 해제해주는지 알아보았다.
먼저 테스트용 프로젝트를 만들었다. 프로젝트 초기 단계에서는 Addressables를 사용하기는 생각보다 간단했다. Package Manager에 추가하고, Addressables를 체크한 다음, 그룹 설정 등을 해주고 기본 Build를 해주면 로컬 메모리에 잘 생성되고, 잘 로드되는 등 생각보다 사용하기가 어렵지는 않았다. (로컬 기준)
결과: AssetBundle1의 Prefab을 로드할 때 AssetBundle2의 TestSprite도 같이 로드되었고, AssetBundle1의 Prefab을 ReleaseInstance로 Release할 때 AssetBundle2의 TestSprite도 같이 Release되었다. (메모리에서 삭제됨)
Addressables로 번들을 빌드할 때 생성되는 addressables_content_state.bin 파일을 이용하면 버전 관리를 수월하게 할 수 있는 것 같다. 해당 파일을 사용하여 빌드하면 Catalog를 새로 생성하는 것이 아니라 기존의 Catalog에서 수정된 번들에 대해서만 변경을 해줘서 변경이 있는 AssetBundle만 다운로드 받도록 할 수 있는 것으로 보인다. 버전을 관리할 때는 각 버전에 대한 빌드 내용과 빌드 당시의 Catalog 파일, addressables_content_state.bin을 같이 백업하면 될 것 같음.
위 내용들을 통해서 우리의 요구사항은 충족할 수 있는 것으로 보이지만... Addressables로 교체하면서 소요될 시간, 발생할 문제에 대처할 시간과 우리에게 남은 시간, 해야할 일 등을 고려해봤을 때 지금 도입하기에는 조금 어려움이 있을 것 같아서 (가능하다면) 다음 프로젝트에서 적용하기로 하였다.
조금 아쉽긴 하지만, 지금도 Shader Varint Stripping을 통해서 상당한 용량의 메모리를 확보했기 때문에 이전에 비해서는 부담이 많이 줄어들어서 도입이 시급하지는 않을 것 같다.
현재는 Shader Variant Stripping을 좀 더 효율적으로 하기 위해서 Shader Variant를 인위적으로 Compile되도록 하여 사용하는 Shader Variant를 수집하는 작업을 하고 있다. 아마 이 작업이 잘 된다면 Shader Variant Stripping에 대한 내용도 포스트 할 것 같다.