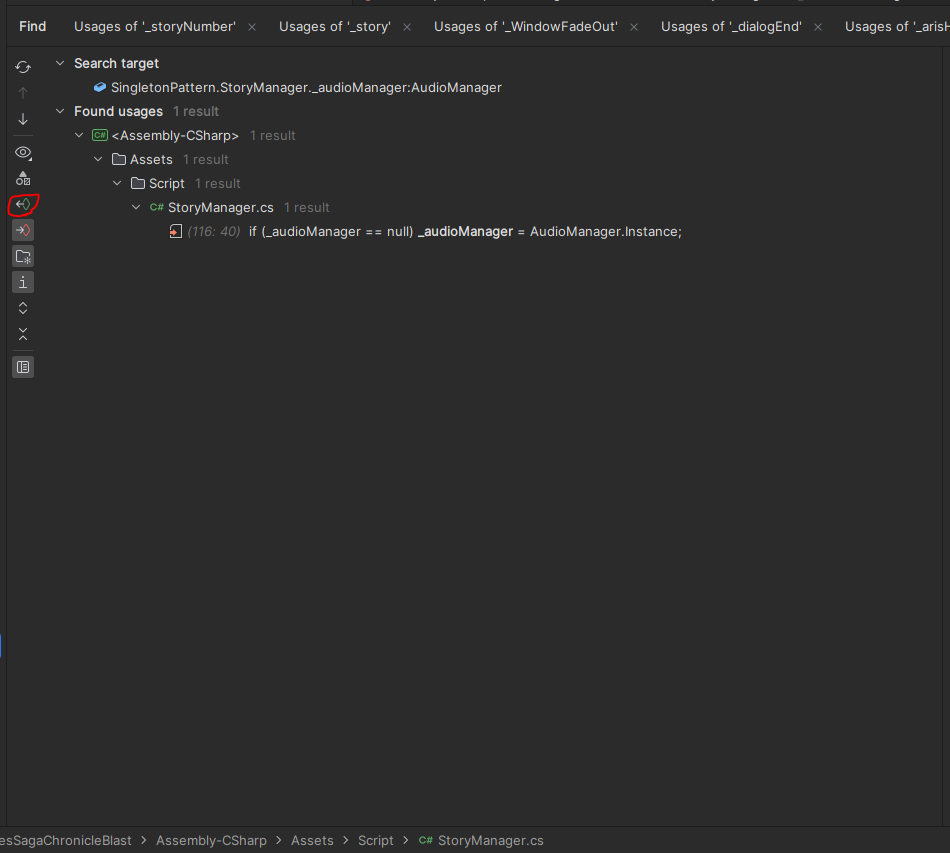
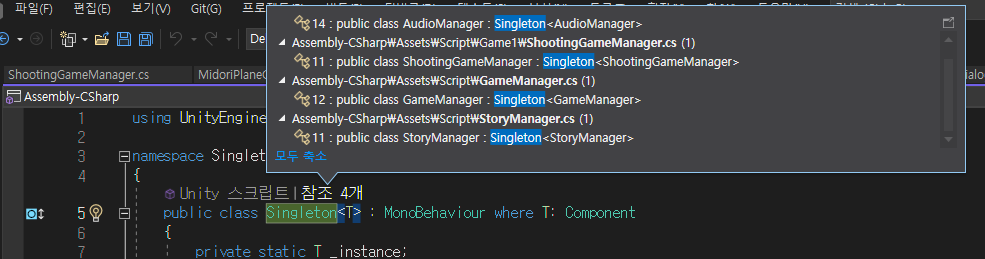
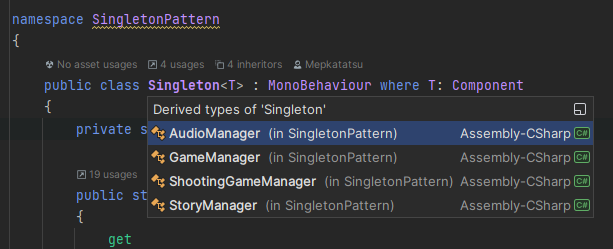
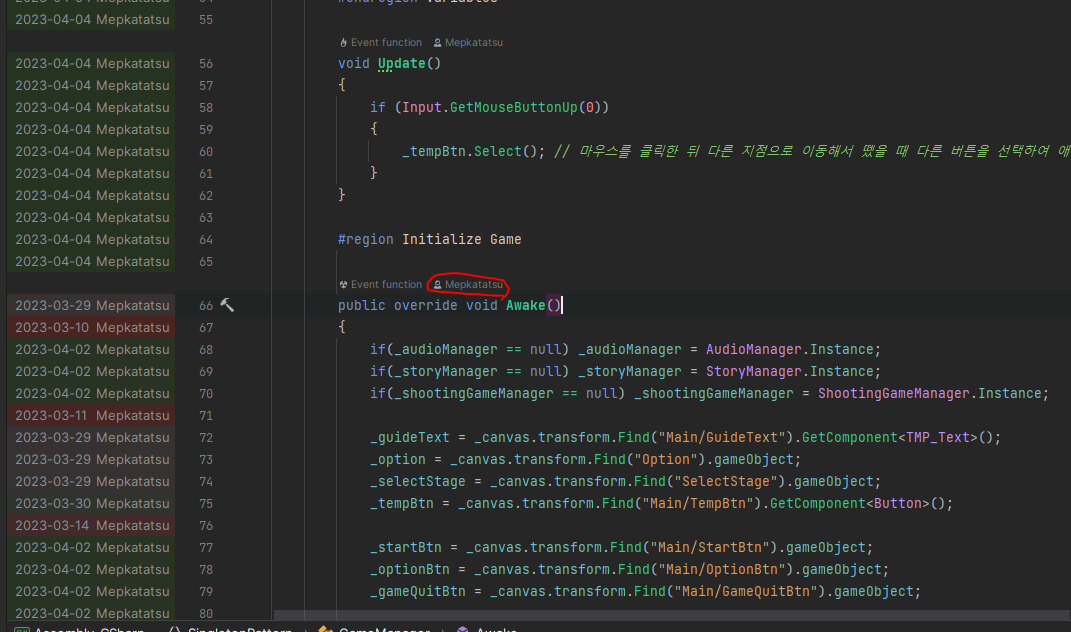
이전에 라이더 글을 쓰면서 코드를 봤는데, 막연하게 굉장히 쓰레기같은 코드를 짜놨을 거라 생각했는데, 의외로 괜찮은 부분도 있었고 구조적으로 문제가 있는 부분도 꽤나 있었다.
이번 기회에 작성했던 코드들을 보면서 어떤 문제가 있었고, 어떤 방식으로 대체하면 좋을지를 적어보고자 한다. 그리고... 가능하다면 그 개선 작업도 차근차근 할 수 있으면 좋겠다. ㅋㅋ.
루트 폴더부터 알파벳 순으로 정리할 예정이다.
Script 폴더
[AudioManager.cs]
FadeOutMusic()
볼륨을 0.01f씩 빼는 게 아니라 (볼륨 / 100)을 변수로 둬서 항상 1초에 걸쳐서 페이드 아웃되도록 수정하면 좋을 것 같다.
어차피 SetBGMVolume, GetVolume 1번씩만 할 거면 굳이 따로 volume 변수 만들 필요 없을 것 같다.
_isBGMChanged 말고 FadeOutMusic을 저장해뒀다가 PlayBGM할 때 코루틴을 중단하는 것이 좀 더 깔끔할 것 같음.
매개변수에 p_ 없애기
Sound를 SerializeField에 때려박는 건 별로 안 좋은 것 같다. 테이블 만들어서 관리하면 좋을 듯.
[ButtonManager]
굳이 버튼 매니저까진 필요 없을 듯 한데... 그냥 관련 스크립트에 추가해서 쓰는 것이 직관적일 듯.
현재는 유니티 에디터에서 OnClick을 설정해주는데, 어떤 버튼이 어디서 사용되는지 추적이 힘들고, 함수 변경할 때마다 참조가 끊어지니 재설정을 해줘야 한다. 코드에서 추가하도록 변경하자.
[DialogManager]
테이블로 관리하자.
[GameManager]
Find는 인스펙터에서 매번 등록하기가 번거롭고 종종 참조가 끊어지는 경우가 있어서 사용했었는데, 구조 변경에 너무 취약하니 빼고 인스펙터에 등록하자.
변수 이름들 수정하기.
\n부분 \r\n으로 변경하자.
로컬라이징도 테이블로 하자. (키값으로 언어 설정에 맞는 텍스트 받아오도록)
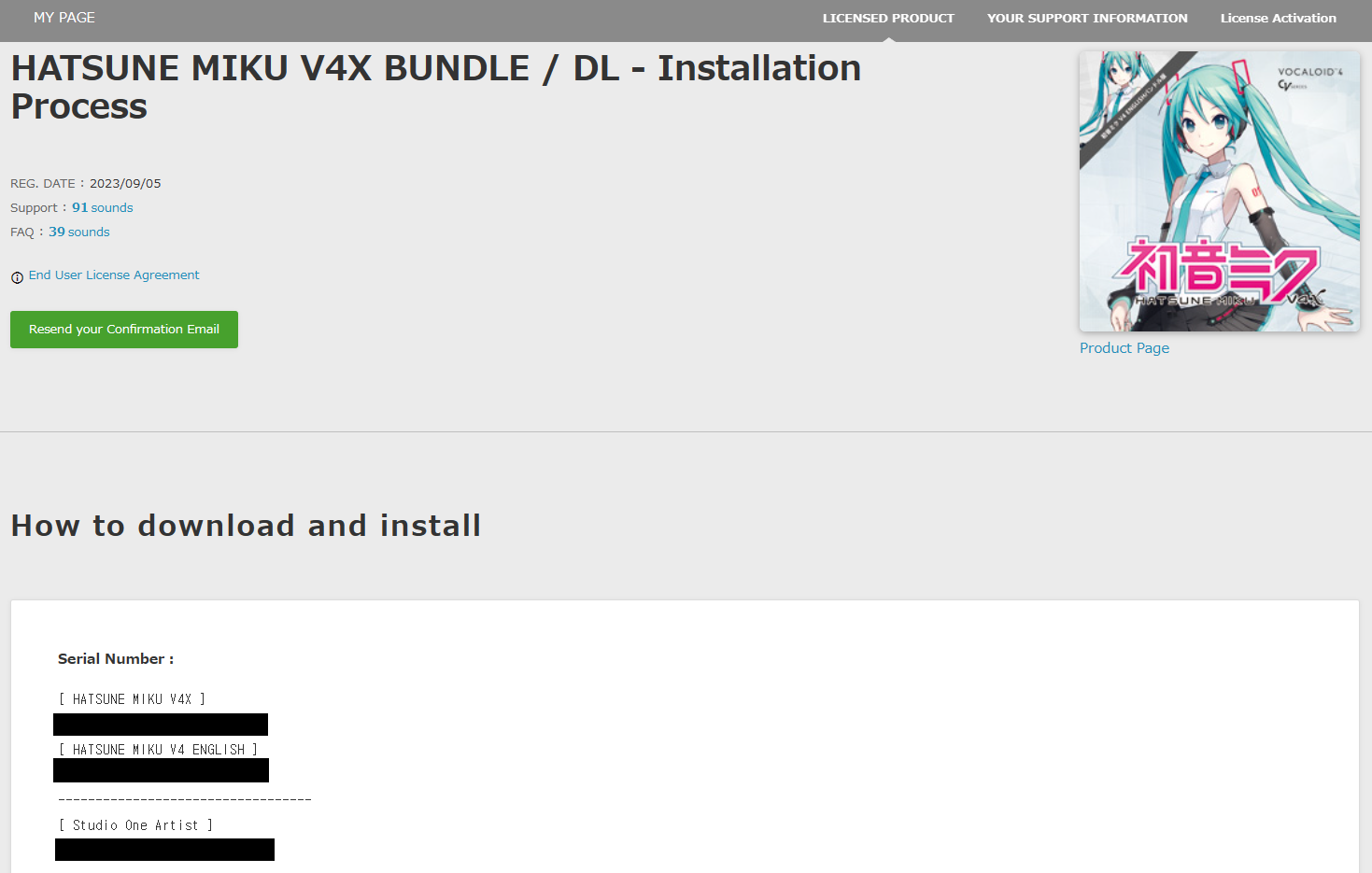
PlayerPrefs.HasKey("Stage1Cleared")
이게 1~4까지 있는데, 현재 몇 스테이지까지 진행했는지만 가지고 있으면 될 것 같다
FadeInImage, FadeOutImage가 GameManager에 있을 이유가 없을 것 같다. 이외에도 필요 없는 것 있으면 분리하기.
필요없는 것들 수정하면 코드가 상당히 짧아질 것 같음. GameManager보다는 좀 더 적절한 이름이 있을 것 같다. IntroManager... 싱글톤도 필요 없을 수도. 그러면 IntroController쯤 되려나?
[SliderController]
Awake에만 초기화가 있어도 될 것 같은데...
아마 Awake 이전에 다른 함수들이 호출되었던 것 같다. OnEnable을 하면 해결되려나?
슬라이더도 인스펙터에 추가하고 이벤트 달아줄 수 있으면 좋을 것 같다.
[StoryManager]
음... 굉장히 끔찍한 코드다. 일단 DoStoryAction()만 다르게 처리되어도 상당히 짧아질 수 있을 것 같다.
한 씬에 때려박는 것보다 씬 전환이 나을 것 같다.
선택지 관련도 뭔가 테이블로 처리할 수 있으면 좋겠다. 선택지 뿐만 아니라 스토리 전체적으로 가능하면 좋을 것 같은데 약간 어려울 것 같다. 기똥찬 방법을 고민해봐야 할 듯. 몇 가지 행동들을 정의해놓고 에디터에서 진행을 구성할 수 있도록 툴을 만들고, 이걸 json으로 바꿔서 번호를 매긴 다음에 각 번호에 해당하는 스토리를 진행할 때 이걸 다시 파싱해서 스토리 액션을 취하는 방식?
원래도 이런 걸 하고 싶었는데 그땐 모르는 게 너무 많아서 못했었다. 지금이라면 해볼 수 있을 것 같다.
전체적인 구조 개선이 필요할 것 같은데 굉장히 힘든 작업이 될 것 같다. 천천히 해보면 좋은 경험이 될 듯.
Script/Game1 폴더
[BulletController]
아군의 공격만 해당되는 것 같아서 MidoriBullet이라고 이름을 바꾸면 좋을 듯
[EnemyController]
StopAllCoroutines() 말고 명확하게 코루틴을 저장해놓고 정지해주는 방법이 좋을 것 같다.
BossController는 분리하면 좋을 것 같은데... EnemyController를 상속받아서 사용하게끔 하면 될 듯?
보스 스킬은 숫자 4 이런식말고 최소한 const로 선언해서 하든가 하는 게 좋을 듯
[LazerController]
함수가 좀 긴 것 같아서 분리 가능하면 분리하면 좋을 것 같다.
총알 사라지는 처리는 나쁘지 않은데 레이저는 살짝 짤리는 문제가 있어서 아예 왼쪽 오른쪽 공간을 덮어버리면 어떨지 확인해보기
-> 아마도 스토리에서 바로 보여주는 식이라 미도리 일러스트 순서때문에 그랬던 것 같은데... 잠깐 부모를 바꾼다거나 하는 식으로 하면 어떨까 싶음
[MidoriPlaneController]
굳이 Controller라는 이름을 붙여야만 했을까? 떼도 괜찮을 듯.
EnemyController도 걍 ShootingGameEnemy라고 하면 될 것 같다.
[ShootingGameManager]
ㅋㅋ 기능 분리가 좀 필요할 것 같다. 슈팅 게임 만들면서 사용할 기능들을 전부 하나에 때려박아서... 오브젝트 풀링이나 LookRotation2D 등은 밖으로 꺼내서 활용해도 될 것 같음.
CreateNewMidoriHalo() 등은 거의 비슷한 코드들이라 하나로 묶어서 처리하도록 처리하면 좋을 것 같다.
여기는 기능은 유지하되 전체적으로 코드 정리가 필요할 것 같다.
[StarColorController]
별들 하나하나마다 반짝거리는 시퀀스를 추가해줘서 성능상 좀 부담이 있을까 싶기도 한데 폰으로 했을 때도 딱히 렉걸리는 건 없었던 것 같아서 이대로 유지해도 괜찮을 것 같음.
단, DOTween.Sequence의 Loop가 GameObject의 active 상태가 false가 되면 멈춘다는 확인이 필요할 것 같다.
JetBrains Rider는 JetBrains사에서 개발한 IDE이다. Visual Studio와 비슷하다고 생각하면 된다.
이전부터 관심은 있었는데 얼마 전에 직장 동료가 할인 소식을 알려줘서 다행히도 저렴한 가격에 구입할 수 있었고, 약 1주+@간 이용해본 소감은... 돈이 아깝지 않을 정도로 굉장히 만족스럽게 사용하고 있다.
그래서 이번 주 스터디는 Rider를 잘 써보자는 차원에서 Rider의 장점이나 활용법 등을 준비해갔고, 지금 쓰는 글도 약간 이 내용을 다듬어서 Rider의 장점을 정리하고, 효율적인 개발을 할 수 있도록 권장해보고자 한다.
IDE(통합 개발 환경) : 코딩, 디버그, 컴파일, 배포 등 프로그램 개발에 관련된 모든 작업을 하나의 프로그램 안에서 처리하는 환경을 제공하는 소프트웨어
IDLE
Visual Studio
Dev-C++
Eclipse
PyCharm
Jupyter Notebook
Android Studio
Visual Studio Code
Rider
…
IDE에는 다양한 종류가 있는데, 내가 사용해본 IDE는 위와 같다. 대략적으로 서술한 순서대로 사용했던 것 같다. Python의 IDLE은 고등학교 정보 시간에, 그 밑으로는 대학교 때, Visual Studio Code는 이전 직장에서 TypeScript를 사용하면서, 마지막으로 Rider는 현 직장에서 사용해보게 되었다.
JetBrains사에서 제시하는 Rider의 장점들과, 그에 해당한다고 생각하는 내용에 대해서 정리해보겠다.
원래 자료는 회사에서 짰던 코드로 만들어서 이전에 내가 만들었던 코드를 열어서 살펴보면서 자료를 만들도록 하겠다. 굉장히 냄새나는 코드들이 많을 것으로 예상한다. ㅋㅋ.
탁월한 코드 분석
Rider는 오류 및 코드 스멜을 탐지하도록 도와주는 2200여 개의 실시간 코드 검사 기능을 자랑합니다. 1000개가 넘는 빠른 수정 기능도 제공되어 탐지된 문제를 개별적으로 또는 일괄적으로 해결합니다. 그저 Alt+Enter를 눌러 하나를 선택하기만 하면 됩니다. 프로젝트 내 오류를 전체적으로 보려면 솔루션 전체 오류 분석(SWEA)을 사용하세요. 이 도구는 코드 베이스의 오류를 모니터링하여 문제가 생겼을 때 텍스트 에디터에 문제 파일이 열려 있지 않아도 알려줍니다.
코드 가독성 향상 (예시)
음... 똥스멜이 나는 코드다. Rider가 switch로 바꿀 수 있다고 추천해준다. 참고로 초록색 점선은 바꿔도 되고, 안 바꿔도 된다는 뜻이다.
Alt+Enter, Enter를 입력하면...?
Rider가 향기나도록 바꿔준다. 음~
이 경우는 미리 선언할 필요가 없다.
쓸 때 바로 선언할 수 있도록 바꿔준다.
변수명/함수명 교정 (예시)
이름은 대체로 맞춰서 짓긴 했는데, 미처 발견 못한 오타가 있었다. XRightEnd를 XRIghtEnd라고 적었던 모양이다.
규칙에 어긋나는 경우에는 저렇게 초록색으로 밑줄을 그어준다. 가끔 노란색으로 그어주는 경우도 있는데 차이는 잘 모르겠다. 내부에서 판단하기를 "이거는 문제 없는 것일 수도?" 라고 생각하면 초록색, "이건 명백히 잘못됐다" 하면 노란색으로 그어주는 것 같다.
참고로, 원하는 코드 스타일을 설정에 저장해놓고 내 입맛에 맞는 코드를 작성할 수도 있다.
대충 이런 느낌이다. C#에서는 지역 변수는 _로 시작하는 것이 보편적이기 때문에 수정하라고 밑줄을 그어준다.
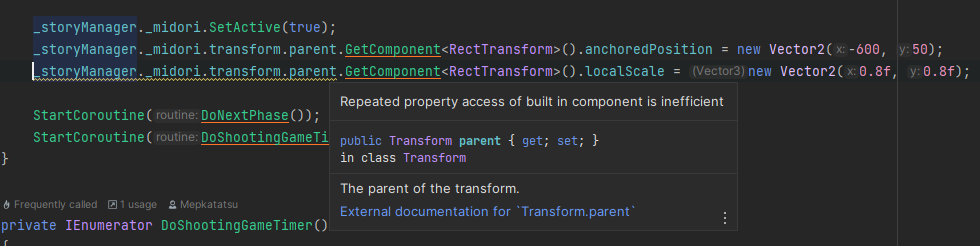
비효율적인 코드 수정 (예시)
위의 경우는 같은 컴포넌트에 연속적으로 접근하기 때문에 캐싱해놓고 쓰는 것이 효율이 좋다.
Rider의 조언을 받아들이면 코드가 이렇게 변한다. 효율도 좋아지고 코드도 조금 더 보기 깔끔해졌다.
유니티에 대한 지식도 있어서 이런식으로 Tag를 직접적으로 비교하는 것보다는 CompareTag를 사용하라고 권장해준다. 아마 내 기억에 gameObject.tag는 string을 하나 만들어 반환하면서 가비지를 생성하는 것으로 알고 있다.
무거운 함수 표시
또, Rider는 주황색 밑줄로 무거운 함수를 표시해준다.
지금은 위 코드가 처음 1번만 실행되는 함수라 신경을 쓰지 않아도 괜찮지만, 예를 들어서 위 코드가 update문에서 돌아가고 있는 코드라면?
매 번 GetComponent를 하는 것보다는 Awake에서 1번만 캐싱해놓고 재활용을 하는 것이 성능상 이점이 클 것이다.
이런식으로, 무거운 함수를 따로 표시해주기 때문에 코드를 짤 때 한 번 더 효율에 대해 고민해볼 수 있게 해준다.
private으로 전환 가능한 것들을 알려줌
public으로 되어있지만, 내부에서만 사용된 코드들은 private으로 전환할 수 있기 때문에 전환 가능하다는 것을 알려준다. 주로 이전에 public으로 만들어서 밖에서 쓰고 있었다가, 다른 함수를 통해 부르는 등의 경우에 이렇게 되는데, private으로 선언해서 해당 함수로만 접근 가능하도록 변환해주면 헷갈릴 여지가 적을 것이다.
자동 완성이 똑똑함
이전에 내내 Visual Studio에서 작업했는데도 불구하고 Visual Studio는 이상한 함수를 추천해준다. 특히나 유니티의, 잘 쓰이지 않는 함수를 뜬금없이 추천하곤 해서 약간 불편하다.
같은 지점에서 동일한 문제를 쳐보면, 완전히 다른 결과가 나온다.
Rider는 지역 함수/최근에 선언한 함수/사용한 것 위주로 추천해주는 느낌이다. 때문에 코드 작성이 훨씬 편해진다.
+듣기로는 이번에 사용할 변수도 예측해서 자동완성을 해준다고 한다.
탐색 및 검색
파일, 유형 또는 코드 내 멤버 어디로든 이동하고 설정 및 액션을 검색하세요. 일반 Search Everywhere(전체 검색) 단축키로 모두 수행할 수 있습니다. 여러 언어 또는 문자열 리터럴에서의 사용 위치를 포함해 어떤 심볼의 사용 위치든 검색할 수 있습니다. 컨텍스트 탐색의 경우, Navigate To(다음으로 이동) 단축키 하나로 심볼에서 해당 심볼의 베이스 및 파생 심볼, 확장 메서드, 구현으로 이동할 수 있습니다.
Getter와 Setter가 구분된다.
위와 같이 Visual Studio에서는 "모든 참조 보기"를 누르면 getter와 setter의 구분이 없이 보여준다.
rider에서는 이런 식으로 보이는데, 초록색으로 나가는 모양이 Getter로써 사용된 부분이다.
왼쪽의 초록색 부분을 눌러 Getter 부분을 끄면, Setter로 사용된 부분만 볼 수 있다.
위 예시는 구분하기 쉬운 경우라서 크게 대단해보이지 않는데, 정말 여기저기 쓰인 변수의 Set 부분이 어딘지 찾으려고 눈이 빠지게 쳐다보는 경우가 아주 가끔 있는데, 이 기능이 있으면 그렇게 목빠지게 쳐다볼 이유가 없다!
상속 받은 것만 따로 볼 수 있음
Visual Studio에서는 Class의 참조를 보면 상속된 경우와 사용된 경우가 같이 보인다.
Rider에서는 상속된 경우만 따로 나타나서 보기가 더 편하다.
위 경우는 상속만 되고 사용된 경우가 없어서 별 차이 없어보이지만, 약 100군데에 사용되었고 그중 약 10군데에 상속되었다고 하면 훨씬 보기가 편하다.
Git 변경 내역을 통해 누가 작성한 코드인지 바로 알 수 있음
빨간색으로 동그라미를 친 부분을 누르면 깃 수정 내역을 바로 왼쪽에서 볼 수 있다.
혼자 작업하는 경우는 상관없지만, 공동 작업을 하다보면 도움이 많이 되는 기능이다.
"누가 작성한 코드지?" (물어보려고)
"아씨... 누가 작성한 코드지?" (원망하려고)
두 경우에 Git을 뒤져볼 필요 없이 바로 누가 작성한 코드인지 알 수 있으니 시간도 많이 절약된다!
언제 수정된 것인지도 알 수 있는데, 이 시기를 금방 알 수 있는 것도 코드 이해에 도움이 되는 경우가 있다.
참고로, 해당 내용은 브랜치에서 머지해온 경우 머지한 사람의 이름이 나오기 때문에 오해의 소지가 있을 수도 있다.
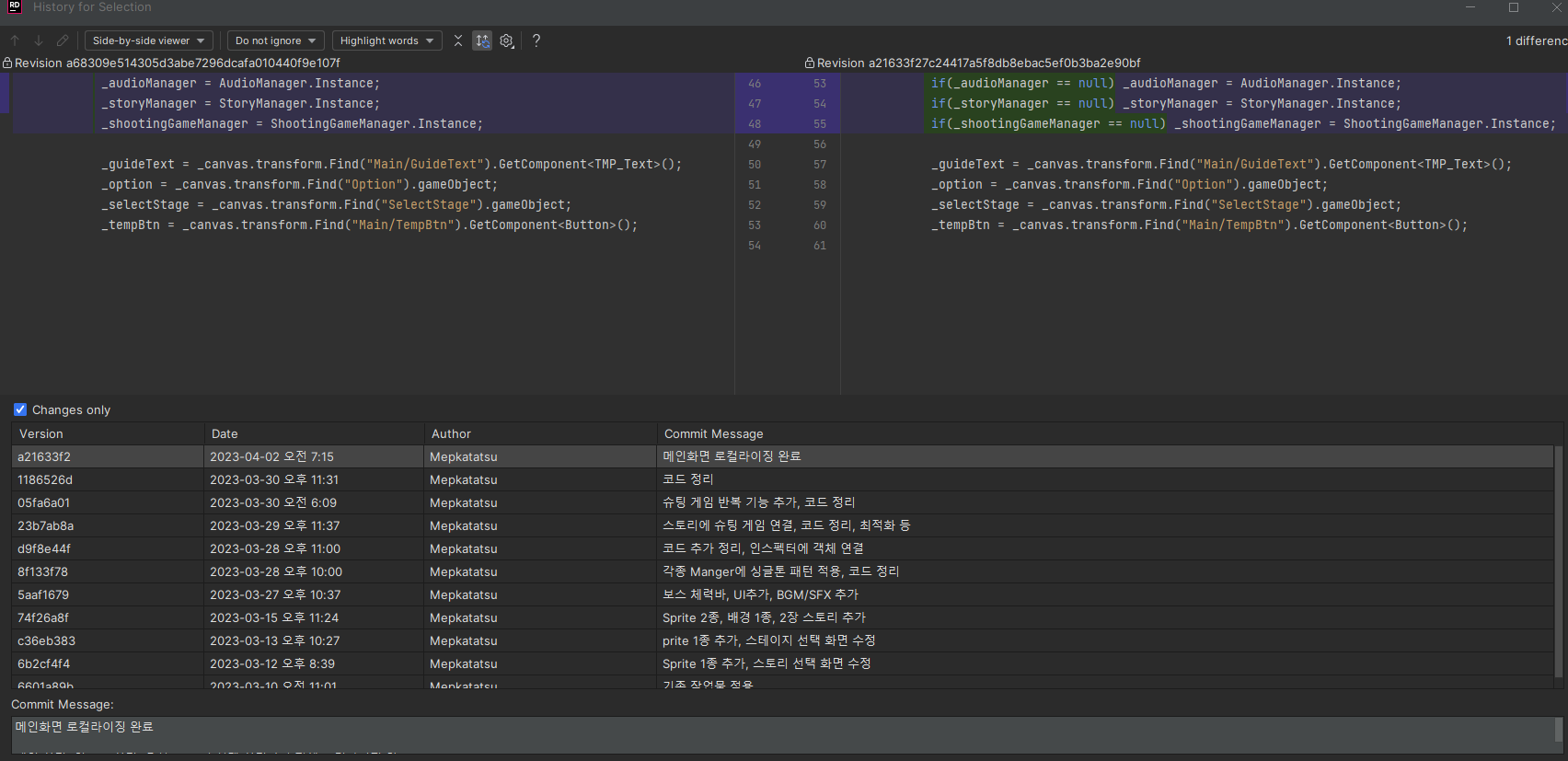
좀 더 자세히 보고 싶다면 원하는 영역을 드래그하고, 우클릭 -> Git -> Show History for Selection 으로 변경 내역을 볼 수있다.
이렇게 커밋 내역과 누가 작성한 것인지, 무엇이 바뀌었는지 바로 나타나서 엄청나게 편리한 기능이다.
깃 내역을 지금 다시보니 짧은 구간이지만 뭔가 예전에 열심히 했던 것 같아서 괜히 기분이 좋다. ㅎㅎ.
TODO
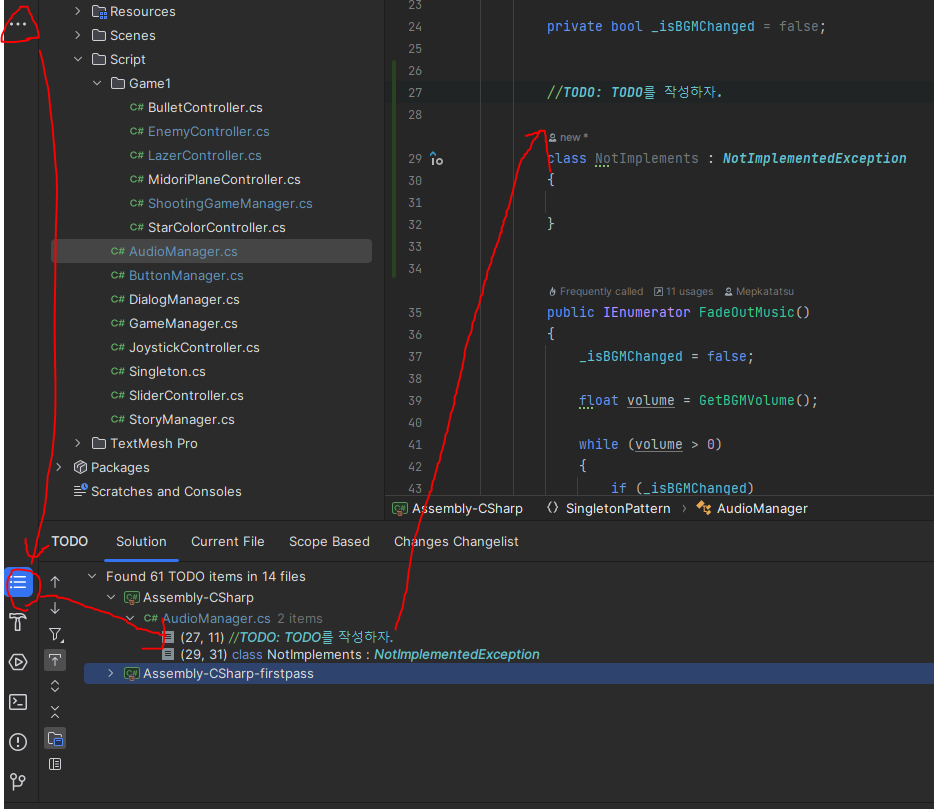
TODO를 모아서 볼 수 있다.
Visual Studio도 TODO를 모아서 보는 기능은 있다지만 접근성이 안 좋아서 그런지 한 번도 써본 적이 없는데, Rider는 상당히 간편하다. 추가로 NotImplementedException 등과 같이 Rider가 판단한 TODO도 기록된다.
원래는 상속받아서 구현할 함수를 구현 안하고 기본으로 넣으면 저게 들어가는데 이때 상속을 아예 안써서 넣을 게 없어서 저렇게 했다. -_-;;
Unity 관련 기능
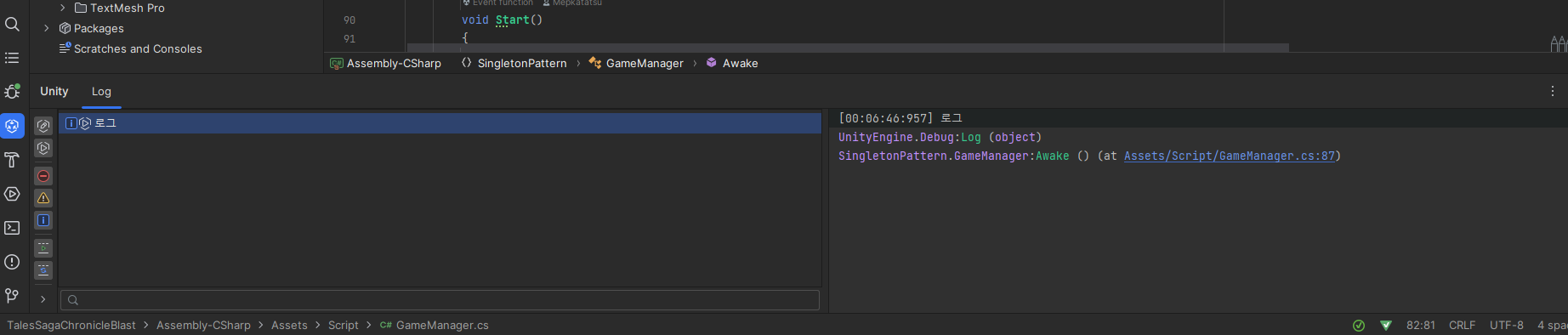
Unity 로그가 표시됨
라이더랑 유니티 에디터 연결만 해주면 Unity 로그가 Rider에도 나타나며 원하는 호출 스택으로 간편하게 바로 이동할 수 있다.
에디터에서 실수로 재시작해서 날아갔어도 Rider에서 따로 날리지 않으면 안 날아가서 다시 볼 수 있어서 굳이 Editor.log 찾아가서 뒤지는 것보다 더 편리하다.
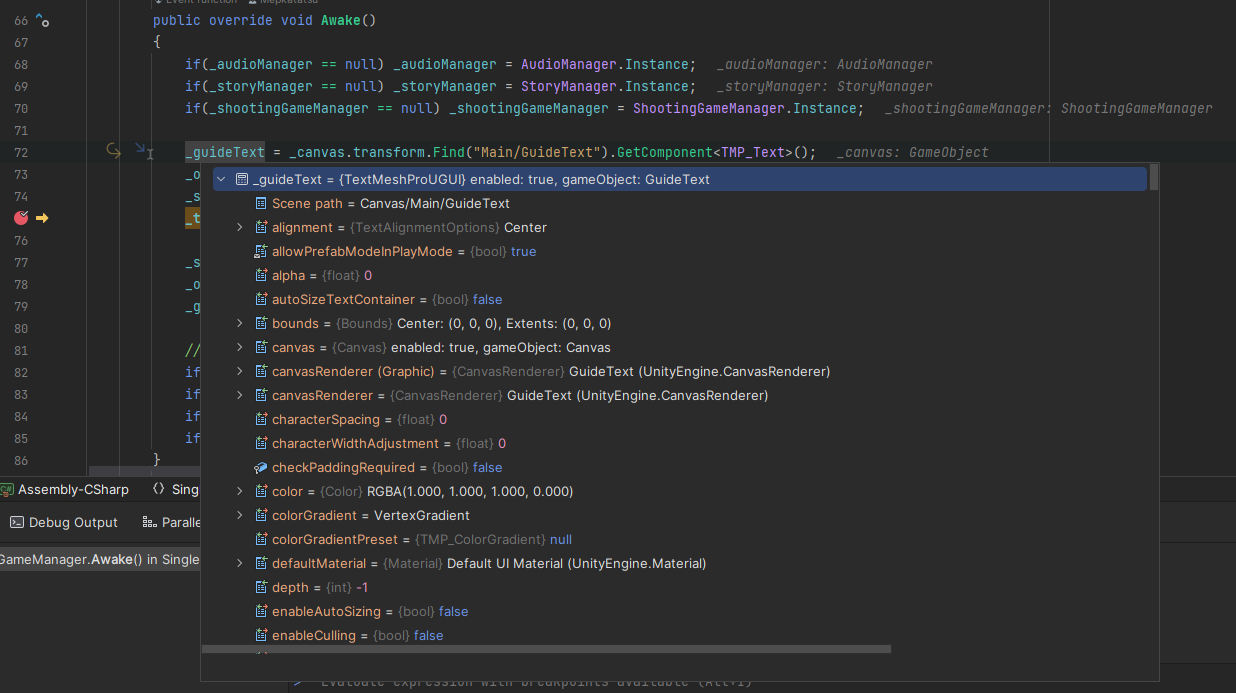
Unity Editor 관련 정보가 뜸
디버그할 때 현재 씬의 어떤 오브젝트에 붙어있는지 경로를 상세히 알려준다. (사진에서 보이는 Canvas/Main/GuideText)
이외에 해당 Component의 정보들도 상세히 알려준다.
상단에서 Unity Editor 실행을 제어할 수 있음
상단에서 실행/일시 정지 등을 제어할 수 있다.
+유니티 에디터에 디버깅 연결하고 끊을 때 Visual Studio를 사용할 때보다 훨씬 빠르다.
Visual Studio의 경우 보통 빨라도 10초 이상 걸리고, 끊거나 할 때도 멈추는 등의 문제가 있는데 라이더는 5초정도면 빠릿빠릿하게 붙고 떨어지는 것 같다. 여태 멈춘 적도 없어서 디버깅도 굉장히 빨라졌다.
디버깅
중단점에 조건거는 것이 간편함
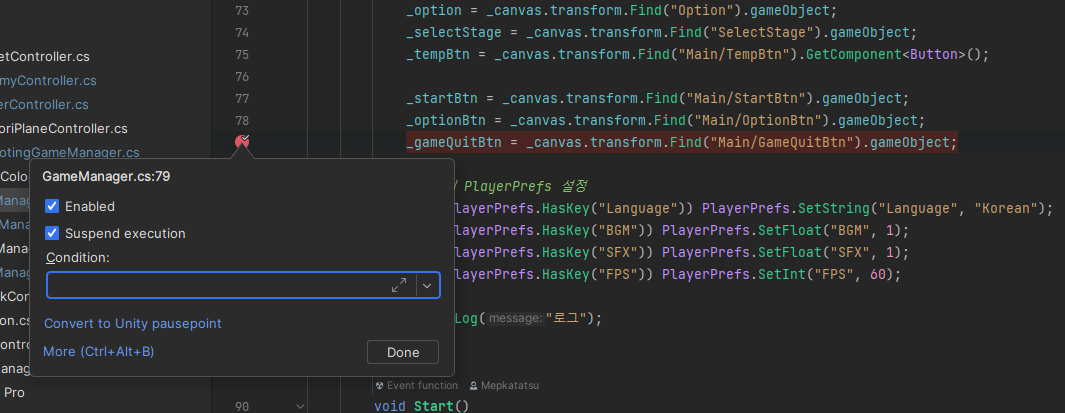
중단점을 걸고 우클릭을 하면 Condition에서 바로 조건을 걸 수 있다.
Visual Studio에서도 있는 기능인 것으로 아는데 쓰기가 불편해서 잘 사용하지 않았는데, Rider에서는 굉장히 간편하게 쓸 수 있다. 또, 인텔리센스의 도움을 받아 자동 완성도 가능하다.
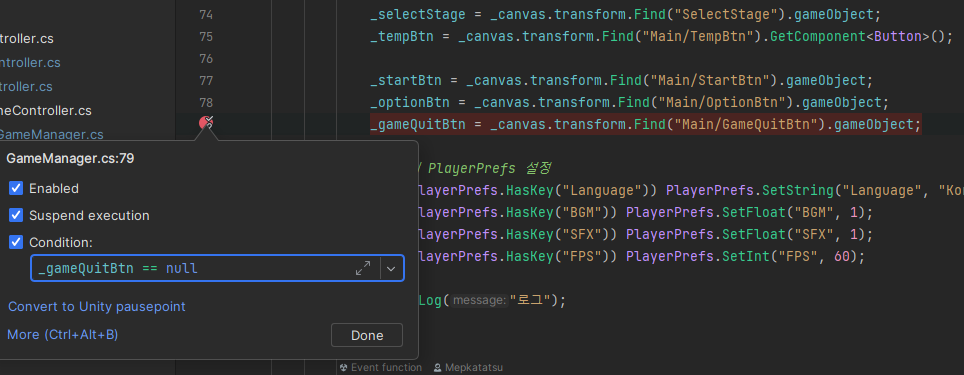
이런 식으로 조건을 걸 수 있다. 위 경우에는, _gameQuitBtn == null 인 경우에만 멈추라는 의미이다.
*** 다만, 조심해야 하는 점은, 조건에 함수도 넣을 수 있지만 여기서 사용하는 함수가 값을 바꿔버리면 예상치 못한 문제가 발생할 수 있다. ***
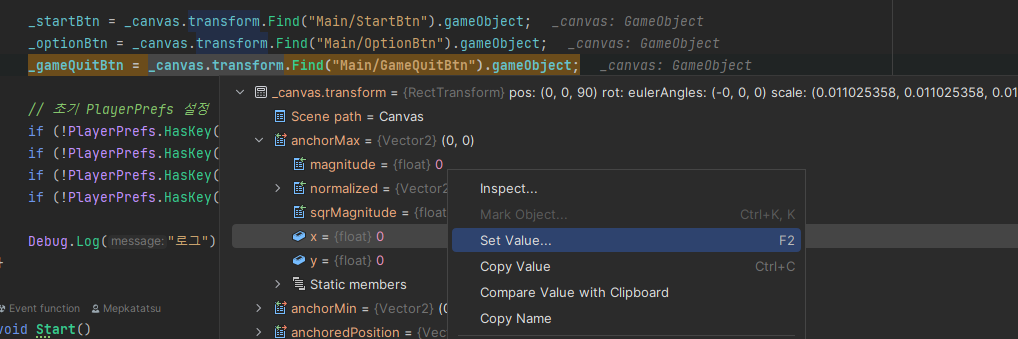
디버그를 하면서 값을 변경할 수 있음
디버그를 하면서 Set Value로 원하는 값을 변경할 수 있다.
다만, 몇 가지 제한이 있고 잘못 넣으면 오류가 생기니 조심해서 사용해야 할 듯.
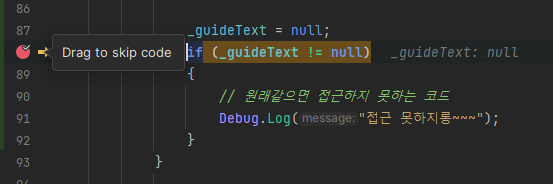
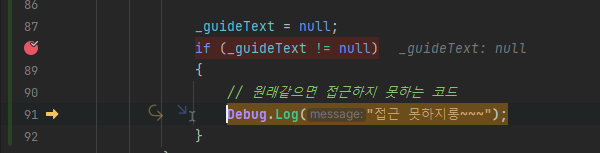
디버그를 하면서 중단점에서 코드 이동이 상대적으로 자유로움
중단점 옆의 화살표를 드래그해서 코드 진행 상황을 이동할 수 있다.
Visual Studio에서도 가능하다는 것 같기는 한데, Rider에서 더 자유롭다고 한다.
원래 아래를 진행중이었는데, 위로 돌아간 모습이다. 아래로도 이동이 가능하다.
추가로, 위 코드는 원래같으면 접근하지 못하는 코드다.
_guideText = null을 선언한 직후이기에 null이라 조건문에서 걸릴 것이다.
하지만 이런 식으로 끌어서 강제로 접근시킬 수도 있다.
단, 왔다갔다 하면서 값이 바뀌거나 예상치 못한 문제들이 생길 수 있으니 주의하자.
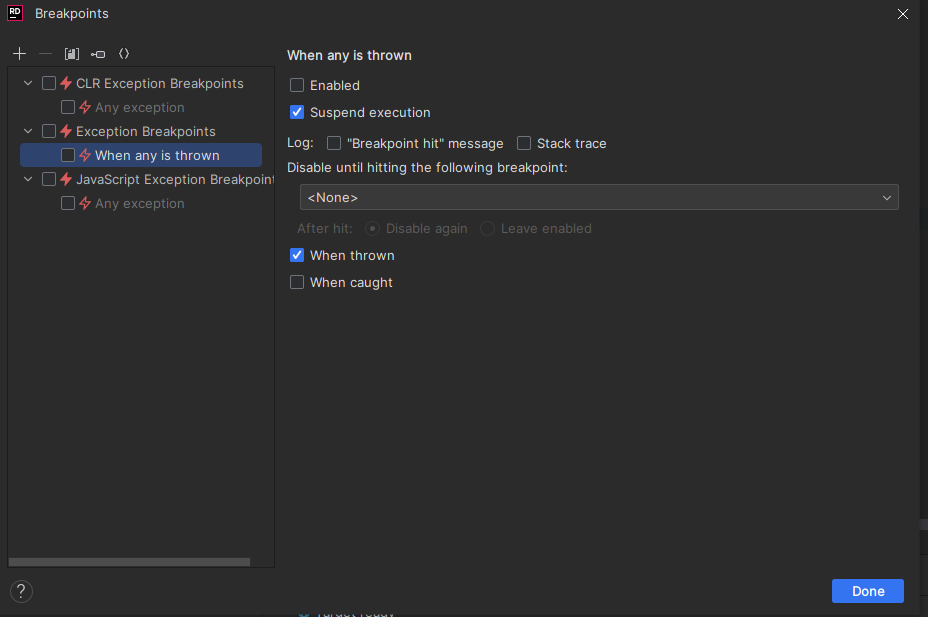
Try Catch에서 Catch가 발생했을 때 바로 Catch로 가지 않고 Exception이 발생한 부분 표시
Ctrl + Alt + B를 누르면 위와 같은 창이 뜨는데, CLR Exception Breakpoints 쪽인지, Exception Breakpoints 쪽인지 정확히는 모르겠지만 Enabled를 체크해주면 try-catch문에서 Exception이 발생했을 때 바로 catch로 넘어가지 않고 Exception이 발생한 부분을 표시해준다고 한다. 뭐... 둘 다 체크해도 괜찮을 듯?
이외에도...
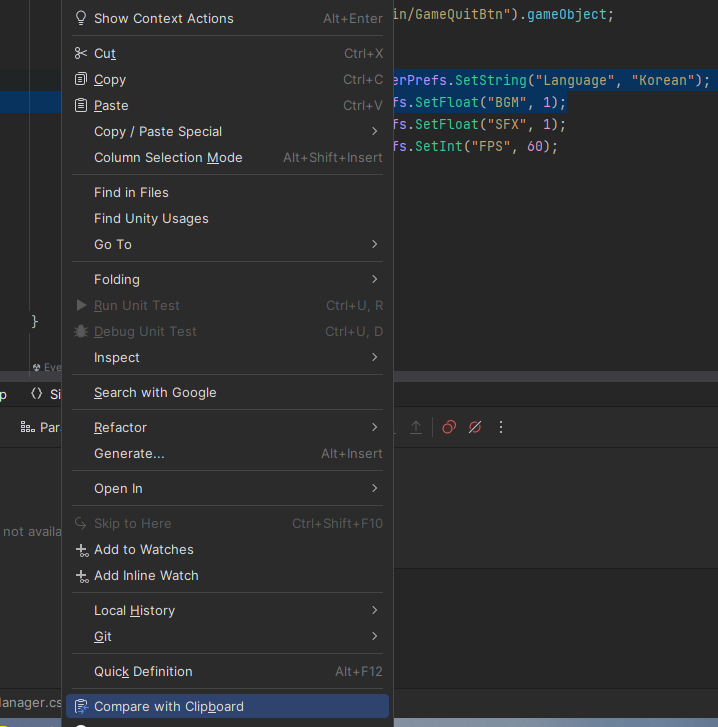
클립보드에 복사한 것과 선택한 영역을 비교하는 기능
두 개가 비슷한 경우 어떤 값이 다른지 눈에 띄게 확인할 수 있다.
Alt + \ 로 멤버 변수/함수에 빠르게 접근이 가능함
이것도 Visual Studio에 있던 기능인 것 같기는 한데... 나름 편리한 기능인 것 같다.
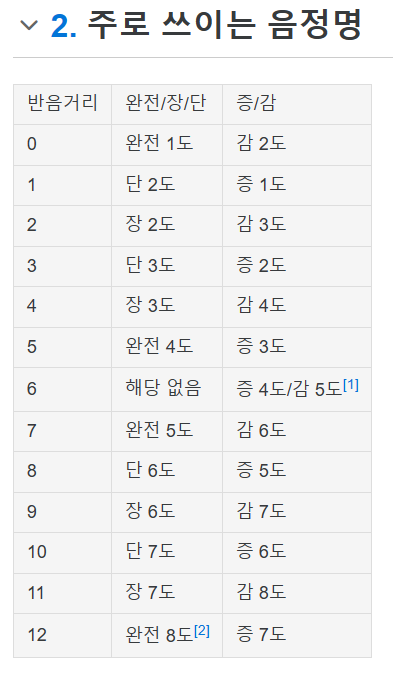
작곡을 하기 전에 음정이라는 개념은 알아두면 좋을 것 같다. 음정이란, 두 음 사이의 거리를 나타내는 표현이다.
예를 들어, 도에서 솔까지의 반음거리는 7이다. 도에서 파까지의 반음거리는 5이다.
물론 반음거리로도 음정을 표현할 수는 있지만... 각 반음거리에 이름을 붙여서 조금 더 알아듣기 좋고, 의미도 이해하기 좋도록 만든 것 같다.
음정 - 나무위키 (namu.wiki)
음정은 위와 같이 표현하는데, 나는 처음에는 왜 2개의 표현이 존재하는지 궁금했다. 완전/장/단 표현과 증/감 표현이 분리된, 별개의 표현이 아니라 같이 쓰이는 표현이라는 점을 알아두면 좋을 것 같다.
먼저 완전/장/단 표현을 살펴보겠다.
도를 기준으로 보면, 자기 자신인 "도"는 1도고, 소리가 완전히 잘 어울리기 때문에 완전 1도라고 한다.
반음거리 1은, 도#이기도 하고 레b이기도 하다. (음정을 따질 때는 편의상 검은 건반은 플랫으로 보면 좋다.)
반음거리 2는 레이다.
때문에 반음거리 1, 2는 "2도" 라고 표현하는데, 반음거리가 2인 경우가 조금 더 멀리 가기 때문에 장 2도, 반음거리가 1인 경우가 장 2도에서 짧아졌기 때문에 단 2도라고 표현한다고 보면 될 것 같다.
참고로, 장 N도의 경우 파->도->솔->레->라->미->시 처럼 솔 이후로 주파수가 2:3 비율인 음들이 포함된다.
3도는 2도와 동일하다.
4도의 경우는 조금 특별한데, 미와 파 사이에는 검은 건반이 없다. 그래서 완전/장/단 표현에서 4도는 완전 4도 하나만 존재한다.
4도와 비교해보면 5도도 특별해지는데, 반음거리 6인 솔b이 있음에도 불구하고 표현이 존재하지 않으며, 완전 5도라고 표현한다.
왜 완전 4도, 완전 5도라고 표현하는지에 대해서는 이전 글에서 언급했듯, 주파수가 2:3 비율이기 때문에 기준이 되는 음(도)와 잘 어울리는 음이기 때문이라고 생각한다. 자기 자신은 당연히 잘 어울리기 때문에 1, 8도를 완전 1도, 완전 8도라고 표현하며, 5도는 주파수가 2:3 비율이기 때문에 가장 어울리는 소리를 내기 때문에 완전 5도라고 표현하는 것으로 보인다. 도에서 오른쪽으로 7반음을 가면 완전 5도인 솔인데, 왼쪽으로 7반음을 가면 4도인 파가 나온다. 이를 1옥타브 올리면 도와 파는 주파수가 3:4 비율이라 솔만큼은 아니지만 굉장히 잘 어울리는 소리가 되고, 이 때문에 완전 4도라고 표현하는 것으로 생각된다.
6도, 7도는 2도와 동일하다.
8도는 자기 자신이기 때문에 완전 8도라고 표현한다.
다음으로는 증/감 표현을 보겠다.
증/감 표현은 C, D, E, F와 같은 음을 기준으로 음정을 계산한다고 생각하면 조금 이해하기가 쉽다.
E -> G를 생각해보자.
미, 파, 솔이기 때문에 3도일 것이고, 미와 파 사이에는 검은 건반이 없기 때문에 단 3도다.
E -> Gb은 어떨까?
위와 같이 생각해보면 단 3도에서 반음 줄은 셈이다. 완전/장/단 표현으로는 장 2도라고 할 수 있겠지만, 일관성이 없는 느낌이다. 때문에 단 3도에서 반음 줄었다는 표현으로써 "감 3도"를 사용한다고 생각하면 된다.
E -> G#은 어떨까?
단 3도에서 반음이 증가했는데, 단 3도가 장 3도에서 반음 감소한 것이기 때문에 장 3도라고 표현하면 된다.
이번에는 C -> E를 생각해보자.
도, 레, 미이기 때문에 장 3도이다.
C -> E#은 어떨까?
장 3도에서 반음 늘었는데, 완전 4도라고 표현할 수도 있지만 경우에 따라 장 6도에서 #이 추가되면 단 7도로 표현하게 될 수도 있다. 마찬가지로 일관성이 부족하니 장 3도에서 반음 늘었다는 표현으로써 "증 3도"라는 표현을 사용한다고 생각하면 된다.
완전 4도, 완전 5도의 경우 반음 줄면 감 4도/감 5도, 반음 늘어나면 증 4도/증 5도라고 표현할 수 있다.
때문에 반음거리가 6인 경우는 증 4도라고도 표현할 수 있고, 감 5도라고도 표현할 수 있는 셈이다.
참고로 완전/장/단 표현에서는 반음거리가 6인 경우가 비어있다. 반음거리가 6인 경우는 트라이톤이라고 하는데, 어울리지 않는, 약간 불안한 소리가 난다. 중세 기독교에서 부정적으로 여기는 음이라고 하여 이 음을 사용하는 것을 피했다고 한다. 때문에 완전/장/단 표현에서 빠진 것이 아닌가 싶다. 그리고 이를 보완하기 위해서 증/감 표현이 생겨난 것은 아닐지... 라는 생각을 하고 있다.
이전에 썼던 내용을 다시 보면 트라이톤에 대한 내용도 꽤나 흥미롭게 인식할 수 있다.
파 -> 도 -> 솔 -> 레 -> 라 -> 미 -> 시 -> 파# -> 도# -> 솔# -> 레# -> 라# -> 파
도, 솔, 레, 라, 미, 시, 파#
도를 기준으로 파#은 6반음거리, 즉 2:3 비율로 6번이나 거쳐가야 나오는 음이다.
파#, 도#, 솔#, 레#, 라#, 파, 도
도를 기준으로 왼쪽으로 가더라도 6반음거리, 2:3 비율로 6번인 거쳐가야 나오는 음이다.
즉, 순정률을 기준으로 도와 파#, 6반음거리에 있는 음이 가장 어울리지 않는 음이라고 볼 수 있는 셈이다.
마찬가지로 반음거리가 1인 도와 도#은 오른쪽으로는 7번, 왼쪽으로는 5번 거쳐야 하므로 트라이톤 다음으로 불안정한 소리가 난다. (시의 경우는 반대이다.) 사람마다 느끼기는 다르겠지만 나는 같이 쳤을 때 트라이톤보다 이 반음거리 1인 소리가 훨씬 어긋나게 들린다고 느껴진다.
배음
배음 - 나무위키 (namu.wiki)
배음이란, 기본음으로부터 정수 배의 진동수를 갖는 음을 말한다.
악기들은 기본적으로 공명을 한다. 공명이란... 특정한 진동이 가진 진동수와 정수배의 진동수를 가진 진동이 만나서 진폭이 증가하는... 현상이라고 보면 될 것 같다.
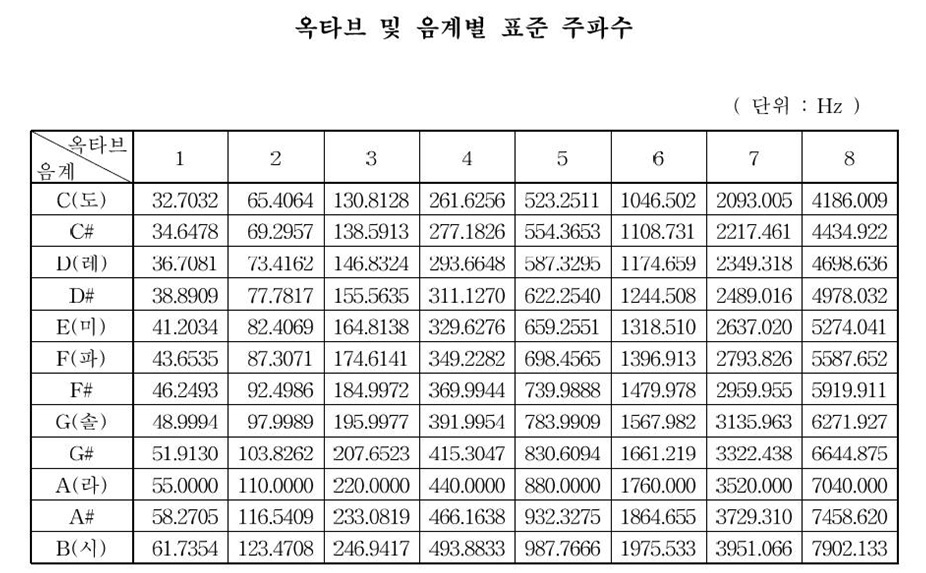
예를 들어서 32.7Hz의 진동수를 가지는 C1의 소리를 피아노로 낸다고 해보자. 참고로 소리 자체가 진동이다. 이 C1의 소리를 내면 악기 내부에서, 악기에 부딪혀 악기가 울린다든가, 악기에 맞고 반사되어 나온다든가, 하여 아마 자기네들끼리 공명을 일으킬 것이다. 이 경우 32.7Hz의 2배, 3배, 4배, 5배, 6배, ... 에 해당하는 진동이 만들어지고, 이 진동으로 인해 발생하는 소리가 배음이라고 할 수 있을 것 같다.
참고로 Minor Scale 말고도 위 블로그 내용이 굉장히 상세하고 이해하기 좋게 되어 있어서 화성학 관련 글들을 한 번 쯤 읽어보는 것을 추천한다.
(단 3도, 단 3도), (단 3도, 장 3도), (장 3도, 단 3도), (장 3도, 장 3도) 까지는 규칙적이라 좀 이해하기 쉬운데, 코드에도 이단(?)이 존재한다. sus2와 sus4가 그 예이다.
sus2는 근음을 기준으로 장 2도, 완전 5도인 음으로 구성되어 있다. (예: 도, 레, 솔)
sus4는 근음을 기준으로 장 4도, 완전 5도인 음으로 구성되어 있다. (예: 도, 파, 솔)
sus2와 sus4는 클래식보다는 재즈에서 많이 사용하는 코드라고 한다.
4화음(7th)
4화음은 3화음 위에 음을 1개 더 올린 화음이다.
1도 화음은 3화음이면 도미솔, 4화음이면 도미솔시가 되는 식이다. 아까 설명한 배음에서 7배음이 시b(보다 약간 낮은 음)라서 아마 시를 붙이는 것 같다.
4화음은 1도, 3도, 5도, 7도로 이루어져 있기 때문에 7th라고도 부른다.
뮤직필드 - 악기/음악 인터넷강좌 (musicfield.co.kr)
C Major Chord의 4화음은 위와 같이 되어있다.
maj7은 Major Chord인데 7th라고 하는 표현이고, m7도 마찬가지로 minor Chord인데 7th라는 표현이다.
m7b5는, minor Chord의 7th인데, 5음이 반음 내려간(b) 코드라는 뜻, 즉 dinimished의 7th라는 표현이다.
Major Chord는 Δ라고도 표현한다. IMaj7, Imaj7, IΔ7, 혹은 IM이라고도 한다.
다이아토닉 코드
다이아토닉 코드는, 어떤 스케일의 구성음으로만 이루어진 코드를 의미한다.
C Major Scale에서는 도레미파솔라시... 로만 이루어져 있으면 다이아토닉 코드인 셈이다.
즉, 위에서 얘기한 1~7도 화음은 전부 다이아토닉 코드이다.
그러나, 만약에, C Major Scale에서 D Major Chord를 사용한다면...
D, F#, A(레, 파#, 라)
스케일의 구성음이 아닌 파#이 사용되었기 때문에 이런 코드를 논다이아토닉 코드라고 한다.
뭐... 보통은 스케일의 구성음을 주로 사용하지만 노래 중간에 색다른 느낌을 주기 위해서 일부러 논다이아토닉 노트(스케일의 구성음이 아닌 노트)를 사용하는 경우가 있는 것 같다.
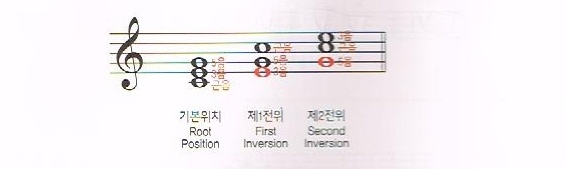
전위
전위는, 위치를 바꾼다는 뜻이다.
(제)1전위는 코드의 근음인 1음을 1옥타브 위로 올리는 것이다.
(제)2전위는 코드의 1음과 3음을 1옥타브 위로 올리는 것이다.
(화성학 기초 - 기초음악이론 - 작곡) 7. 전위 (음의 중복, 생략, 은복, 병행) : 네이버 블로그 (naver.com)
즉, 위 그림처럼 1전위를 하면 3음이 베이스 음이 되고, 2전위를 하면 5음이 베이스 음이 된다.
3화음은 3전위를 하면 그냥 전체적으로 1옥타브를 올린 셈이라 3전위라는 표현을 사용하지는 않지만, 4화음은 7음을 베이스 음으로 하는 3전위라는 표현을 사용할 수 있다.
분수 코드(슬래시 코드)
이건 뇌피셜이지만, 보통은 코드를 칠 때 한 옥타브 아래의 근음을 같이 쳐주는 경우가 많은 것 같다.
이 경우 음이 상당히 풍성하게 느껴지는데, 아마도 이 한 옥타브 아래의 근음을 치면서 나오는 배음들이 코드와 잘 어울리기 때문에 그러는 것으로 추정된다.
때문의 C코드를 C3에서 연주한다면... 왼손은 C2를, 오른손은 C3, E3, G3를 치는 셈이다.
그런데 오른손은 C코드를 치는데, 왼손은 E를 치는 경우도 있을 것이다.
이 경우 C/E 라고 표현하는데, 이것이 슬래시 코드(분수 코드)이다.
C가 왼쪽에 있긴 하지만, 1/2의 경우 2가 밑에 있고 1이 위에 있듯... C/E도 E가 밑에 있기 때문에 아래쪽 음을 담당하는 왼손이 E를 친다고 생각하면 편할 것 같다.
추가로, 왼손을 사용하지 않는 경우는 전위에 따라 베이스 음의 위치에 따라 슬래시 코드를 표기하는 것 같다.
토닉, 도미넌트, 서브 도미넌트
각 Scale의 첫 음을 으뜸음, 5번째 음을 딸림음, 이런 식으로 표현하는데, 7번째 음은 이끎음(이끔음)이라고 한다.
이끔음은 으뜸음으로 가려는 성질이 있다고 한다. 즉, C Major Scale에서 시 -> 도 로 가려는 성질이 있다는 셈이다. 이와 비슷하게 파도 파 -> 미 로 가려는 성질이 있다고 한다. 다만, 시 -> 도 로 가려는 성질이 훨씬 크고, 파 -> 미로 가려는 성질은 조금 뭐랄까, 부차적인 느낌인 것 같다.
왜 이런 성질이 있는지는... 음... 잘 모르겠다. 어디에도 이와 관련된 설명이 없고, 레딧에 이와 관련된 질문이 있던데, 답은 "그냥" 인 것 같다. 음... 뭐... 과거부터 노래들이 그래왔기 때문에 관습처럼 자리잡았다고 생각하는 편이 정신 건강에 이로울 것 같다.
적절한 예시인지는 모르겠지만... 영화에서 "이 전쟁에서 살아서 돌아간다면 그녀에게 고백할 거야" 라고 한 사람은 반드시 죽을 것이다 라고 생각하는 것이랑 비슷하지 않을까? 이 대사가 나오면 꼭 죽어야 한다는 법은 없지만 여태껏 그래왔기 때문에 이러는 것이 자연스럽다... 라는 느낌?
말하자면 시(B)는 "이 전쟁에서 살아서 돌아간다면 그녀에게 고백할 거야" 인 셈이고, 도(C)는 그 발언을 한 사람이 "이 편지를... 그녀에게 전해줘..." 하며 죽는 장면이라고 생각해도 되지 않을까 싶다.
예시가 적절한지는 모르겠지만, 세상을 살다보면 이해하기 어려운 일들도 많으니 그냥 순순히 받아들이도록 하자...
아무튼, 이렇게 시 -> 도, 파 -> 미 로 가려는 성질을 작곡에 활용하는데, 여기서 토닉, 도미넌트, 서브 도미넌트라는 단어가 등장한다.
토닉은 안정된 화음으로 1, 3, 6도 화음이 이에 해당된다.
도미넌트는 불안정한 화음으로 안정된 화음으로 이끌리는 성질이 있다. 5도 화음이 이에 해당된다.
서브 도미넌트는 도미넌트와 비슷하지만 약간 모자란, 토닉도 도미넌트도 아닌 애매한 포지션에 있으며 토닉과 도미넌트 사이를 연결해준다고 보면 될 것 같다.
음... 얘네는 글이 살짝 이상해질 수 있을 것 같지만 내가 생각한대로 적어보겠다.
우선 화음의 성질은 3음(2번째 음)이 결정한다는 얘기를 어디서 보았다.
이를 바탕으로 생각해보면...
1도 화음: 도, 미, 솔 -> 전체적으로 안정된 음
3도 화음: 미, 솔, 시 -> 시가 포함되어 있기는 하나... 3음인 솔이 완전 협화음이기 떄문에 안정된 음
6도 화음: 라, 도, 미 -> 전체적으로 안정된 음
5도 화음: 솔, 시, 레 -> 3음인 시가 강한 이끌림을 주기 때문에 도미넌트
4도 화음: 파, 라, 도 -> 3음인 라가 협화음이긴 하지만 불완전 협화음이고 약한 이끌림을 주는 파가 포함되어 있으므로 서브 도미넌트
2도 화음: 레, 파, 라 -> 3음이 파로, 약한 이끌림을 주기 때문에 서브 도미넌트
7도 화음: 시, 레, 파 -> 3음인 레가 불협화음이고, 강한 이끌림을 주는 시와 약한 이끌림을 주는 파가 포함되어 있으므로 서브 도미넌트 (7도 화음을 도미넌트로 보는 경우도 있는 듯 하지만 제외하는 게 보편적인 것 같음)
토닉과 서브 도미넌트는 3개씩 있지만 각각 1, 4도 화음이 메인이고 나머지는 비슷한 역할을 하는 대리화음이라고 생각하면 될 것 같다.
아무튼, 도미넌트는 토닉으로 진행하려는 성질이 있고, 이를 도미넌트 모션이라고 한다.
도미넌트 모션이 나타나면 듣는 사람에게 해결감을 줄 수 있다.
곡의 시작과 끝은 보통 토닉이 들어간다.
이 정도를 알아두면 구성을 대충 짜볼 수 있다.
토닉 -> 도미넌트 -> 토닉
이게 가장 단순한 구성일 것이다.
I -> V -> I
하지만 이러면 너무 단조로우니 중간에 서브 도미넌트를 끼워넣으면 조금 더 다채로워질 수 있다.
토닉 -> 서브 도미넌트 -> 도미넌트 -> 토닉
I -> IV -> V -> I
토닉 -> 도미넌트 -> 서브 도미넌트 -> 토닉
I -> V -> IV -> I
도 가능은 하겠지만, 도미넌트 -> 토닉으로 이동할 때의 해결감이 덜해질 테니 그리 좋지는 않을 듯.
추가로 예시를 들자면...
토닉 -> 서브 도미넌트 -> 도미넌트 -> 토닉
I -> ii -> V -> I
ii -> V -> I 진행이 자주 쓰이는 진행이라고 하는데, 토닉으로 시작하여 처음에 안정감을 주는 느낌의 구성이다.
세컨더리 도미넌트
토닉, 서브 도미넌트, 도미넌트 3종류가 있지만 실질적으로 사용할 수 있는 도미넌트는 5도 화음밖에 없어서 진행이 다소 단조로워질 수 있다. 때문에 인위적으로 "다른 도미넌트"를 만들어서 사용하는데, 이를 세컨더리 도미넌트라고 한다.
예를 들어서 C Major Scale에서 진행을 하고 있다고 치자.
V - I과 같이 도미넌트 모션을 하면 G Maj -> C Maj 진행이 될 것이다.
V - III나 V - VI 도 가능하겠지만, 해결감이 덜 할테고, V - I가 주는 느낌과는 다를 것이다.
V - I 느낌을 주고 싶은데, V - I를 많이 사용해서 식상하다면, 간접적으로 도미넌트를 만들어주는 것이다.
예를 들어서 4도 화음인 F Major Chord를 1도 화음이라고 간주하고, 이에 해당하는 5도 화음을 가져다가 쓰는 것이다.
F Major Chord를 1도 화음이라고 하면, 5도 화음은 C Major Chord가 된다.
즉 다른 Scale에서 코드를 빌려와 C Maj -> F Maj 진행으로 잠시 색다른 V - I 진행을 만들어줄 수 있는 것이다.
related iim도 이와 비슷한데, ii - V - I 진행이 자주 쓰이기 때문에 세컨더리 도미넌트에 해당하는 2도 화음을 만들어서 쓰는 셈이다. F Major Chord가 1도 화음이면, 2도 화음은 G minor Chord가 되겠다. C Major Scale에서 G에 해당하는 Chord는 Major Chord이기 때문에 Non-Diatonic Chord가 쓰이게 되는 셈이다.
이를 통해서 G min -> C Maj -> F Maj 진행으로 ii - V - I 을 색다르게 표현할 수 있다.
아마 써본 적은 없지만, 아무때나 막 쓰는 것은 아니고 자연스럽게 연결할 수 있어야 할 것 같다.
아무튼, 이렇게 이전 글에서 순정률과 조성, 이번 글에서 음정, 배음, 화음에 대해서 알아보았다.
토닉, 도미넌트, 서브 도미넌트에 대한 내용은 이해도 조금 부족하고 설명도 좀 부실한 것 같지만... 전체적으로 얼추 이해를 할 수 있게 된 것 같다.
그리고 이론에 대해서 찾아보면서 많이 들은 것은, 이론이 절대적인 것은 아니고 결국 "듣기 좋으면 장땡" 이다. 나도 "이론을 공부해서 완전히 계산적인 완벽한 노래를 만들어내겠어!" 라는 생각은 당연히 아니고, "작곡에 대해 아무것도 모르기 때문에 이론이라도 공부해서 어떤 식으로 작곡하면 좋을지 알고 싶다"는 차원이었다.
아직 다루지 못한 내용들이 꽤 있긴 하지만... 작곡을 하기 위한 기초적인 지식은 마련이 된 것 같다. 알고 있는 것과 활용할 수 있는 것은 다르기 때문에 이제부터는 다양하게 활용을 해보면서 내가 듣기 좋은 음악을 만들고, 가능하다면 다른 사람들이 만든 음악도 분석해서 어떤 식으로 활용을 했을까도 알아볼 수 있으면 좋을 것 같다.
다음 글은 멜로디를 만드는 것과, 코드를 입혀보는 것을 해볼까 한다. 원래는 피아노 곡을 만들어보려는 계획이 있었는데, 이것도 어차피 멜로디와 코드의 구성이라... 미리 만들어 둔 멜로디를 사용하려고 한다. 그리고 글 제목이 "보컬로이드 하츠네 미쿠를 활용한 작곡"이니 하츠네 미쿠를 써야하지 않겠는가? ㅋㅋ
위 사이트에 들어가면 이용 약관을 볼 수 있다. 평소 약관은 잘 안 읽지만 법은 무서우니 읽어보았다.
기본적으로 내용은 납득할 만한 내용이었다. 구입한 사람만 사용하라든지, 디컴파일 등 하여 내부 소스 코드 까보지 말라든지 등등...
비상업적 용도는 물론 상업적 용도로 사용이 가능하다고 한다. 다만, 이 엔진을 구매하면 하츠네 미쿠의 음성을 사용할 수 있는 권한을 얻은 것이지, 하츠네 미쿠의 상표권은 별개이기 때문에 하츠네 미쿠라는 상표나 캐릭터를 이용하기 위해서는 별도의 절차가 필요하다는 것 같다.
비상업적 용도나 유튜브나 니코니코 동화 등에 업로드 하는 경우에는 딱히 문제가 없는 것 같다.
뭐 그래서 나는 딱히 이용 약관을 위반할 일은 없을 것 같다.
블로그나, 기껏해봐야 유튜브나 니코동 등에 올리는 수준 정도에 그칠테니... 사실 그것도 언제가 될지 모르겠다. ㅋㅋㅋ.
이전에 언젠가 내 마음에 쏙 드는, 다른 사람들에게도 들려주고 싶은 노래를 만들고 싶다고 했었는데, 나는 그정도면 만족할 것 같다. 나 말고도 누군가 한 사람이라도 좋아해주는 사람이 있으면 더 좋을 것 같고.
하지만 현재 수준에서는 그런 곡을 만들기는 어려울 것 같다. 음악에 대해서 깊게 파고들수록 더 모르는 것들이 많다는 것을 알게 된다. 화성악을 통해 이론적인 것은 알았지만 어떻게 그것을 활용할 것인지는 커녕 다른 곡들에서 어떻게 활용하고 있는지조차 느끼기가 어렵다. 하루아침에 되는 일이 아니라 꾸준히 듣고, 공부하면서 익혀야 할 것 같다.
그리고 요즘엔 드럼에 포커스를 맞추면서 듣고 있는데, 드럼의 비트는 어떤 식으로 짜는 것인지도 잘 모르겠다. 이것도 아마 공부할 필요가 있을 것 같다. 베이스도 근음을 사용한다고는 하지만 여러 변형들이 있던데 그런 것도 알아둘 필요가 있을 것이고... 하나하나 차근차근 배워나가는 수밖에 없을 것 같다. 때문에 목표를 세워보았다. 현재 목표는 다음과 같다.
1. 화성학에 대해서 추가로 배운 내용들 정리하기
2. 코드 진행에 익숙해지기
3. 피아노만을 사용하여 반주와 멜로디가 있는 간단한 곡 만들어보기 (1절만)
4. 피아노로 반주를, 하츠네 미쿠로 멜로디를 만들어 간단한 곡 만들어보기 (1개의 곡)
화성학에 대한 부분들은 일단 기본적인 내용들에 대한 개념은 얼추 이해를 한 것 같아서 이번 주 중에 쓸 것 같다.
코드 진행은 아직 잘 모르겠다. 이론적인 부분은 알겠는데, 토닉이나, 도미넌트, 서브 도미넌트... 아직 들으면서 뭐가 토닉이고 뭐가 도미넌트인지 구분하기가 어렵다. 도미넌트 -> 토닉 진행에 해결감이 있다는 얘기를 많이 하는데, 뭔가 느낌적인 부분으로는 알 것도 같은데... 정도라서 조금 익숙해질 필요가 있을 것 같다.
이것도 이번 주 중에 계속 듣고... 늘어지면 다음 주까지도 할 수도 있을 것 같기도 하다.
3번은 1주일 정도면 어떻게 되지 않을까 하는 생각을 가지고 있다. 2번을 하기 위해 직접 코드들을 쳐보면서도 어느 정도 진행할 수 있을 것 같은 느낌이기도 하다.
그러면 3번까지를 이번 달 안에 끝내는 것이 목표가 될 것 같다.
4번은, 글쎄, 3번이랑 비슷할 것 같기는 하지만 발음이나 음 조절 등 조교 등에 익숙해지려면 시간이 꽤 걸리지 않을까 싶다.
그 뒤에는 드럼, 베이스, 기타, 등... 악기들을 하나씩 넣어보면서 숙달시키는 작업을 할 것 같다.
음... 생각만해도 엄청 오래 걸릴 것 같다. 그래도 꾸준히... 하다보면... 언젠가... 음... 잘 하게 되겠지?
8월 10일에 1편을 쓴 이후로 뜸했다. 3주간 많은 시행착오를 거쳤는데, 그 과정에서 주된 활동이 화성학 공부였다.
다뤄본 악기라고는 목소리 정도가 유일한 나에게 음악적 지식이 굉장히 부족하다는 것을 느끼는 것은 그리 오래 걸리지 않았고, 부족한 경험을 채우기 위해서라도 이론적 지식이 필요하다고 생각했다.
무엇부터 배워야 할지 몰라서 빙빙 헤맸는데, 지금은 어렴풋이 갈피를 잡아서, 하츠네 미쿠의 16주년이기도 하여, 여태 배운 내용들을 간략하게 정리를 해보려고 한다.
어떤 내용을 쓸까 집에 오면서 정리해봤는데, 대략 아래의 순서대로 쓸 예정이다. 참고로 나는 아래에서 위로 거의 거꾸로 올라왔다. 덕분에 이해하기는 더럽게 힘들었지만, 퍼즐이 점차 맞춰나가는 것을 느끼며 순정률 부분을 보면서 마음 속으로 탄성을 지를 수 있는 기회를 얻을 수 있었다고 생각한다.
파도솔레라미시에 대한 내용은 위 글이 이해하기 쉽게 되어있는 것 같으니 참고하면 좋을 것 같다.
아무튼, 이렇게 12개의 음이 나온 것이다.
옛날에도 아마 한 번쯤은 들어본 얘기였던 것 같은데, 그때는 별 생각 없었지만 이번엔 머리가 좀 띵했다.
음악도 결국은 수학놀음이었구나! 하고...
참고로 위에 얘기한 내용은 순정률인데, 반음 간의 주파수 차가 일정하지 않다는 문제로 인해 발생한 여러 문제들이 있었고, 이로 인해 현대에서는 반음 간격을 동일하게 나눈 평균율을 많이 사용한다고 한다. 하지만 여전히 듣기 좋은 순정률도 많이 사용한다고 한다.
그래서, 위에서 조성을 얘기하다가 넘어왔는데, 조성이란 무엇인가?
12개의 음 중에서 7개의 음을 사용하기로 정해놓는 것이라고 생각하면 될 것 같다.
다장조는 도레미파솔라시 7개의 음으로 이루어져있는데, 다장조 노래에서 갑자기 도#, 레#, 파#, 솔#, 라# 등의 검은 건반의 소리가 나온다면 상당히 튀는, 어색한 음으로 느껴지게 되는데, 이게 그런 이유인 셈이다.
여기서 이어 왜 7개의 음을 사용할까? 생각을 해봤는데, 12개의 음 중에 주파수가 비슷한 영역을 잘라서 7개의 음을 사용하기로 한 것이 아닐까- 라는 생각을 했다.
아니나 다를까, 방금 찾아보니 그 생각이 맞는 것 같다.
C Major Scale – Piano Music Theory (piano-music-theory.com)
먼저 C Major Scale이다.
파 -> 도 -> 솔 -> 레 -> 라 -> 미 -> 시 -> 파# -> 도# -> 솔# -> 레# -> 라# -> 파
순서에서 파, 도, 솔, 레, 라, 미, 시 로 이루어져있다.
C Sharp Major and D Flat Major Scales – Piano Music Theory (piano-music-theory.com)
C# Major Scale은 어떨까?
파 -> 도 -> 솔 -> 레 -> 라 -> 미 -> 시 -> 파# -> 도# -> 솔# -> 레# -> 라# -> 파
순서에서 파#, 도#, 솔#, 레#, 라#, 파, 도 로 이루어져있다.
D Major Scale – Piano Music Theory (piano-music-theory.com)
D Major Scale도 마찬가지다.
파 -> 도 -> 솔 -> 레 -> 라 -> 미 -> 시 -> 파# -> 도# -> 솔# -> 레# -> 라# -> 파
순서에서 솔, 레, 라, 미, 시, 파#, 도# 으로 이루어져있다.
즉, 조성이란 12개의 음 중에서 구간을 나눠 7개를 사용하는 것이라고 볼 수 있을 것 같다.
다시 다장조를 보자.
C Major Scale – Piano Music Theory (piano-music-theory.com)
다장조는 흰색 건반 7개를 사용하고, 도를 으뜸음으로 하기 때문에 설명하기 좋은, 기본이 되는 조성이라고 생각한다.
위 다장조를 분석해보면 장조, 즉 Major Scale에 대해서 알 수 있다.
뮤직필드 - 악기/음악 인터넷강좌 (musicfield.co.kr)
아까 흰 건반과 검은 건반을 차례대로 하나씩 올라가는 것을 반음이라고 했는데, 흰 건반 -> 검은 건반 -> 흰 건반 이렇게 반음을 2번 움직이면 온음이라고 한다.
도레미파솔라시도를 보면, 도->레 는 온음, 레->미 도 온음이지만, 미-> 파는 중간에 검은 건반이 없기 때문에 반음 관계를 갖는다.
이런 식으로 장조는 온음, 온음, 반음, 온음, 온음, 온음, 반음 관계로 이루어진다.
C Sharp Major and D Flat Major Scales – Piano Music Theory (piano-music-theory.com)
위의 C# Major Scale을 다시 보자.
C#을 으뜸음으로 하며, 마찬가지로 온음, 온음, 반음, 온음, 온음, 온음, 반음 관계로 이루어진 것을 확인할 수 있다.
D Major Scale은 어떨까? D인 레에서 시작해서 온음, 온음, 반음, 온음, 온음, 온음, 반음 관계의 음들을 찾아나가면 D Major Scale을 만들 수 있다.
Major Scale과는 다른, Minor Scale이라는 것이 있다. 우리나라 말로는 단조라고 한다.
단조 중의 기초는 아마 가단조일 것이라고 생각한다.
A Minor Scale – Piano Music Theory (piano-music-theory.com)
이유는 가단조가 다장조와 마찬가지로 흰 건반 7개의 음으로 이루어졌기 때문이다.
가단조는 라시도레미파솔 로 이루어져있는데, 라가 맨 먼저 나오는 이유는 라가 으뜸음이기 때문이다.
으뜸음이란, 음, 뭐라 설명하긴 애매한데(잘 모른다는 뜻), 조성의 대표가 되는 음이다. 음악의 첫 음과 마지막 음은 이 으뜸음이 나오는 경우가 많다.
때문에 C Major Key는 도로 시작해서 도로 끝나지만, A Minor Key는 라로 시작해서 라로 끝나는 경우가 많다는 것이고, C Major Key의 3번째 음인 미는 1번째 음인 도와 4반음거리 차이가 나지만, 가단조의 3번째 음인 도는 1번째 음인 라와 3반음거리 차이가 난다. 이런 이유로 다장조와 가단조는 같은 음으로 구성되어 있지만, 다른 분위기가 나는 것이다. (이건 딱히 찾아본 것은 아니고 여태까지 공부한 것을 바탕으로 생각한 것인데, 아마 맞을 듯.)
Minor Scale은 Major Scale과는 다른 구조로 이루어져있는데, 온음, 반음, 온음, 온음, 반음, 온음, 온음 으로 이루어져있다. 이를 통해서 Major Scale에서 했던 것과 같은 방식으로 다른 키의 Minor Scale을 찾을 수도 있다.
C Sharp Major and D Flat Major Scales – Piano Music Theory (piano-music-theory.com)
다음은 #과 ♭에 대한 이야기다. 위에서 보면 F에 파란색 표시가 있지만 표기는 E#이라고 하고 있다.
E와 F 사이에는 검은 건반이 없기 때문에 E#은 F라고 할 수 있고, F♭은 E라고 할 수 있겠다.
위에서는 왜 E#으로 표기를 해놓았느냐 하면, 우선 이렇게 표기하면 A, B, C, D, E, F, G 를 전부 하나씩 사용해서 표기할 수 있다. 이와 관련해서 Pitch class라는 용어도 있는 것 같다.
또, 조표를 보면 7개에 전부 #이 들어간 것을 볼 수 있다. 만약 E#이 아니라 F를 사용한다면, 조표의 F부분에 #을 빼고, F를 사용할 때는 그냥 쓰고, F#을 쓸 때는 항상 #을 붙여줘야하니 상당히 번거로울 것이다.
위 얘기는 꼭 필요한 얘기는 아니지만, 평소 E#과 F는 같은 것 아닌가? 라는 생각을 잠재우기에 충분한 이야기였기 때문에 넣어보았다.
위 어플은 코드에 대한 이해가 부족하고, 청음에 어려움을 겪어서 구매했는데, 1,100원이라는 가격이라 별 기대는 안 했지만 퀄리티가 꽤나 괜찮은 것 같다. 이론적인 내용들도 영상으로 보여주고, 랜덤한 퀴즈를 맞추는 등의 연습을 할 수 있다. 다만 전부 영어로 되어 있어서 영어를 조금은 알아들을 수 있다면 추천한다.
아무튼, 여태까지 이해한 내용들을 괜찮게 정리한 것 같다.
위에 써놨던 것들 중 일부가 남았는데, 아직 이해도 부족하고 시간도 늦었으니 다음으로 미루도록 하겠다.
혹시 글을 읽다가 잘 모르는 용어가 있다면 찾아보길 권한다. 하나씩 알아가다 보면 전체적인 이해를 얻을 수 있을 것이다. (나도 그렇게 헤쳐나왔다.)
이전 글에서 Addressables에 대한 내용을 다루었었는데, 메모리 관리와 관련해서 추가로 찾은 내용이 있어서 올리고자 한다.
Addressables은 자체적으로 Reference Count를 관리하여 AssetBundle 내의 모든 Asset이 Release되면 AssetBundle을 통째로 자동으로 메모리에서 해제해준다는 내용을 찾아볼 수 있었다.
또, 마찬가지로 AssetBundle끼리도 Reference Count를 가지고 있는 것으로 보였다.
하지만, 각 Asset에 대한 Reference Count는 어떻게 관리를 하는지에 대해서는 찾아보기가 조금 어려웠다.
만약 각각 Asset을 직접 해제해줘야 한다면 작업이 상당히 번거로워질 것이기 때문에, 이점이 크지 않을 것 같았다.
InstantiateAsync와 Release에 대한 개념은 인지하고 있었기 때문에 과연 이 기능이 Asset 내부에서도 Reference Count를 관리해주며 자동으로 메모리를 해제해주는지 알아보았다.
먼저 테스트용 프로젝트를 만들었다. 프로젝트 초기 단계에서는 Addressables를 사용하기는 생각보다 간단했다. Package Manager에 추가하고, Addressables를 체크한 다음, 그룹 설정 등을 해주고 기본 Build를 해주면 로컬 메모리에 잘 생성되고, 잘 로드되는 등 생각보다 사용하기가 어렵지는 않았다. (로컬 기준)
결과: AssetBundle1의 Prefab을 로드할 때 AssetBundle2의 TestSprite도 같이 로드되었고, AssetBundle1의 Prefab을 ReleaseInstance로 Release할 때 AssetBundle2의 TestSprite도 같이 Release되었다. (메모리에서 삭제됨)
Addressables로 번들을 빌드할 때 생성되는 addressables_content_state.bin 파일을 이용하면 버전 관리를 수월하게 할 수 있는 것 같다. 해당 파일을 사용하여 빌드하면 Catalog를 새로 생성하는 것이 아니라 기존의 Catalog에서 수정된 번들에 대해서만 변경을 해줘서 변경이 있는 AssetBundle만 다운로드 받도록 할 수 있는 것으로 보인다. 버전을 관리할 때는 각 버전에 대한 빌드 내용과 빌드 당시의 Catalog 파일, addressables_content_state.bin을 같이 백업하면 될 것 같음.
위 내용들을 통해서 우리의 요구사항은 충족할 수 있는 것으로 보이지만... Addressables로 교체하면서 소요될 시간, 발생할 문제에 대처할 시간과 우리에게 남은 시간, 해야할 일 등을 고려해봤을 때 지금 도입하기에는 조금 어려움이 있을 것 같아서 (가능하다면) 다음 프로젝트에서 적용하기로 하였다.
조금 아쉽긴 하지만, 지금도 Shader Varint Stripping을 통해서 상당한 용량의 메모리를 확보했기 때문에 이전에 비해서는 부담이 많이 줄어들어서 도입이 시급하지는 않을 것 같다.
현재는 Shader Variant Stripping을 좀 더 효율적으로 하기 위해서 Shader Variant를 인위적으로 Compile되도록 하여 사용하는 Shader Variant를 수집하는 작업을 하고 있다. 아마 이 작업이 잘 된다면 Shader Variant Stripping에 대한 내용도 포스트 할 것 같다.
이전에 언급했던, 이번 주에 스터디 자료로 활용할 Addressables 관련 내용을 정리하였다. 추가로 AssetBundle, SBP와 현재까지의 과정에 대한 내용을 함께 구성하여 팀원들의 이해도를 높일 수 있도록 하였다. (만든 자료에서 일부 내용은 수정하여 올림)
이 글로 AssetBundle과 Scriptable Build Pipeline, Addressables에 대한 전반적인 내용을 이해할 수 있기를 바란다.
AssetBundle
Asset Bundle: 특히 모바일 게임에서, 게임에 접속할 때 다운로드 받는 것
사용해야 하는 이유 1:Google Play Store의 앱 크기 제한은 150MB (App Store는 500MB)
가끔 Google Play Store의 제한인 150MB를 초과하는 경우가 있는데, PAD(Play Asset Delivery)를 활용한 것. 최대 1GB(경우에 따라 2GB)까지 에셋 번들을 함께 다운로드 받을 수 있음. 스토어에서 다운받도록 하면 비용이 들지 않기 때문에 활용하면 좋다.
사용해야 하는 이유 2: 데이터 유동성 확보
앱을 통째로 빌드한다면 빌드 시간 소요, 스토어 검수 통과 필요, 플레이어가 업데이트 해야 함.
에셋 번들을 경우, 서버를 내리고 에셋 번들을 업데이트하면 플레이어가 게임 내에서 다운로드를 받을 수 있음. 처리에 걸리는 시간도 훨씬 적기 때문에 버그에 대해 훨씬 유연하게 대처할 수 있음.
단점: 에셋 번들 시스템을 구축하는 과정이 상당히 복잡하다.
다행인 점: 우리는 이미 에셋 번들 시스템이 구축된 상태다.
현재 사용중인 BuildPipeline의 문제점: 압축 방식에 따라 빌드 과정이 분리되어 종속성이 제대로 설정되지 않는다.
종속성: Material이 포함된 Prefab을 Load할 때, 필요한 Material을 먼저 Load하고 Prefab을 로드해야 한다. 그렇지 않으면 Magenta 색을 볼 수 있음. (이 경우 Prefab이 Material에 종속성이 있는 것임)
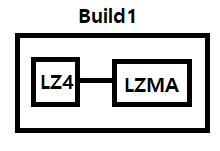
LZ4 방식의 빌드 과정과 LZMA의 빌드 과정이 분리되어 Dependencies가 제대로 설정되지 않음.
LZMA: zip, 7z 등에 사용되는 압축 방식으로, 압축률이 높지만 로딩 속도가 느림.
LZ4: LZMA에 비해 압축률은 낮지만 로딩 속도가 빠르고 효율적이기 때문에, 다운로드를 받을 때만 LZMA로 압축된 번들을 받고 다운받을 때 LZ4로 Recompress하여 디스크에 저장함.
UnCompressed: 비압축 방식으로, 빌드 속도는 빠르겠지만 용량이 굉장히 커지기 때문에 권장하지 않는 방법임. UnCompress보다 LZ4가 첫 로딩 속도가 빠른 것 같다는 내용이 있었는데, 아마 처음 실행할 때 LZ4로 압축하는 과정을 거치는 것이 아닐까 싶음.
Scriptable Build Pipeline
Scriptable Build Pipeline: BuildPipeline보다 유연성 있게 빌드할 수 있도록 제공하는 패키지.
ContentPipeline을 사용하면 압축 방식과 상관없이 빌드가 한꺼번에 이뤄지기 때문에 Dependencies의 손실이 없다.
기존에 사용하던 BuildPipeline과 큰 차이점이 없어서 전체 과정의 일부를 변경하는 것으로 적용되었음. (대략 주황색 정도)
문제점: Shader Stripping이 BuildPipeline과 다른 방식을 거치는 것으로 보인다.
→ Scriptable Build Pipeline에서 Shader Stripping이 제대로 되지 않는다는 내용의 글
→ 기존과 비교해서 삭제되지 않은 것을 수동으로 삭제해주는 것으로 해결했다고 함.
우리도 약 210MB → 약 90MB로 상당 부분 감소함. (화요일)
하지만 여전히 기존의 약 70MB보다는 30%가량 큰 문제가 있음.
대부분의 용량은 Nature Shaders의 Shader에서 차이가 나는데, 이 용량만 줄인다면 Shader의 용량이 기존보다 감소함.
전체 용량으로 보았을 때는 기존의 전체 용량보다 약간이지만 작은 것을 확인하였음. (AnimationClip의 수가 30% 감소하였고, 이외에도 조금씩 변화가 있었음)
다만 바로 적용시키는 것은 꺼려지는데, Nature Shaders의 용량이 변하는 이유를 아직 확인하지 못했기 때문임.
1. IPreProcessShader에서 Shader Stripping이 된 이후에 Shader의 키워드들을 확인했고, 각 Shader에서 사용되는 키워드는 동일한 것을 확인할 수 있었음.
2. 각 Pass에서 사용되는 키워드도 동일한 것을 확인하였음. (BuildPipeline에서는 가끔 Pass에 1개의 키워드가 적게 들어오는 경우가 있었는데, ContentPipeline에서 이 키워드를 삭제하니 용량은 전체적으로 작아졌지만 그래픽에 문제가 생겼고, Grass의 경우 여전히 기존보다 2배 이상 컸음)
3. Log Shader Compilation을 기록해보았으나 BuildPipeline, ContentPipeline 각각의 빌드에서 컴파일 된 셰이더의 컴파일 내용은 완전히 동일했음 (특정 맵 기준)
4. 프레임에 따라 옵션이 바뀌는 기능을 끄고 해봤으나 용량은 동일했음
5. RenderDoc으로 각 경우에서 사용된 Shader를 비교해보았으나 동일한 것으로 추정됨. (Line 수로 판단)
게임 내에서 로드된 Shader에 포함된 정보들을 출력해보았으나 유의미한 결과는 얻을 수 없었음.
6. 에셋에 포함된 Shader에 대한 정보를 볼 수 있는 툴들을 다수 활용해보았으나 ShaderX로 잠겨있어서 내부 정보를 얻을 수 없었음.
7. SBP에 Build Logging에 대한 내용도 있으나 Shader로 검색한 결과 유의미한 결과를 얻을 수 없었음.
→ BuildPipeline을 사용할 때보다 용량이 크다는 문제점은 인식했지만, 원인을 규명하기가 어려움
용량 차이의 문제는 ShaderX를 사용하는 Nature Shaders만 두드러지게 나타남. 나머지는 용량이 동일하거나 차이가 있다고 해도 미미한 수준이었던 것 같음. (Nature Shaders에 Standard가 포함되어 있는 것도 약간 의문이며, 이 Standard에서도 용량 차이가 나타남)
1개의 Shader에서 8개의 Variants를 생성하는 Keyword가 있었는데, 영향은 적지만 차이점을 이해할 수 있는 단서가 될 수도 있을 것 같음. (왜 삭제가 되지 않았는지?)
Shader Stripping에 대한 Insight를 얻어서 현재 사용 중인 Shader Stripping을 더욱 최적화 할 수 있을 것 같음.
현재: 일부 Scene을 돌면서 수동으로 정리한, “전체 Shader에서 사용하지 않는” Keyword들을 삭제해 줌.
개선 가능: Scene들을 돌면서 나온 Log에서 각 Shader에 사용되는 Keyword, 혹은 Variants를 자동으로 추출하여 저장하고, 이를 제외한 Keyword들을 삭제해줌 (자동화, 각 Shader에 대한 최적화)
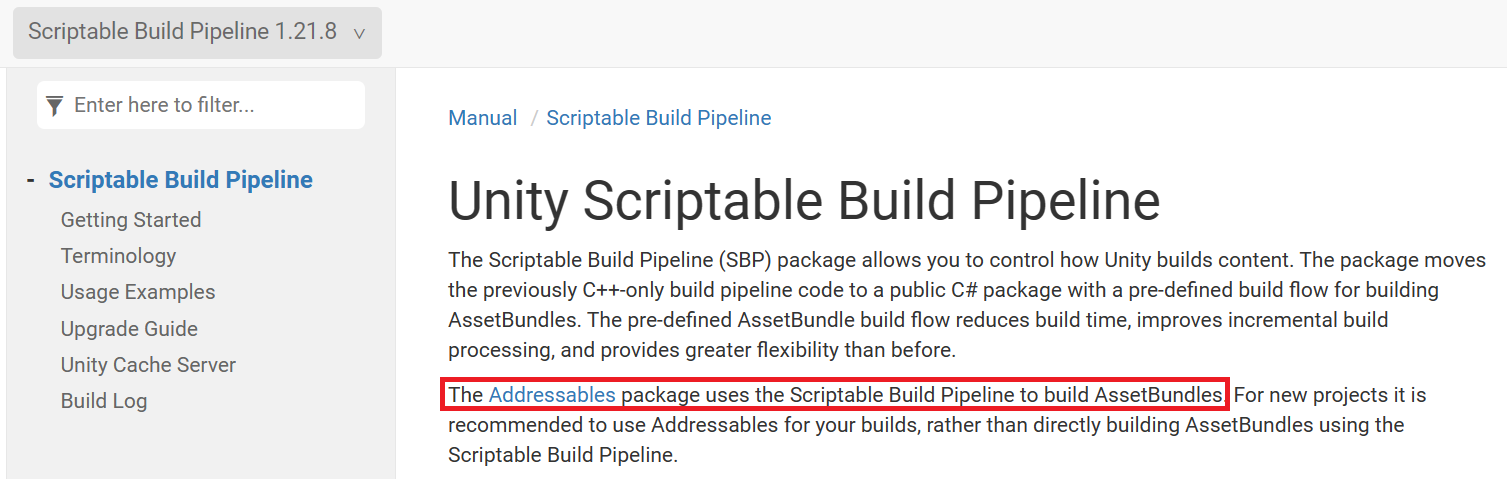
Addressables는 빌드할 때 Scriptable Build Pipeline을 사용한다고 하는데, Addressablse로 바꾼다고 해도 현재와 동일한 문제가 발생할 가능성이 있음. (Shader Stripping 관련)
Addressables: Unity에서 제공하는 Asset Bundle 빌드에 사용하는 최신 Package
[Addressables의 장점]
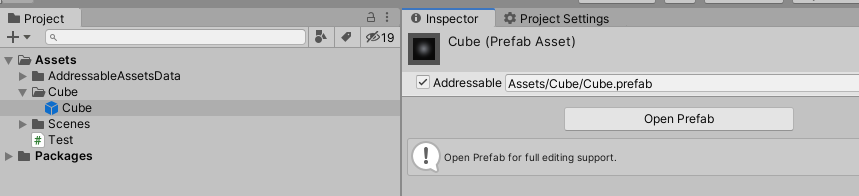
1. 경로 등에 영향을 받지 않는 Address를 사용하여 유연하게 사용 가능 (기본값은 실제 Path)
Addressables 패키지를 받으면 Asset에 위와 같이 Addressables이라는 체크 박스가 생기고, 체크 박스를 체크하면 각 Asset이 고유한 Address를 가질 수 있게 됨. 기본값은 에셋의 실제 Path이며, Adress는 Asset을 수정하거나 경로를 변경해도 유지되기 때문에 실제 Path를 사용하는 것보다 유연하게 사용이 가능함
Asset을 Load할 때 Address로 호출하기 때문에 현재 방식을 그대로 사용할 수 있을 것 같음
2. Addressables 창에서 에디터의 Asset/AssetBundle 중 어떤 것을 로드할지 선택이 가능함
우리는 AssetBundle을 사용하지만 구현되어 있는 기능
3. 종속성 관리를 자동으로 해줌
AssetBundle을 사용하면 AssetBundleA를 로드할 때, 종속성이 있는 다른 번들들을 미리 로드해야 하기 때문에 각 번들의 Dependencies를 체크하고 로드하는 작업을 해줘야 하지만(우리는 구현되어 있음), Addressables는 이것을 자동으로 처리해줌
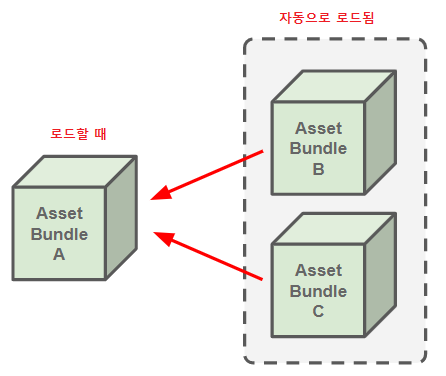
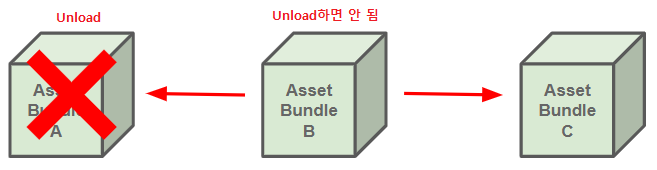
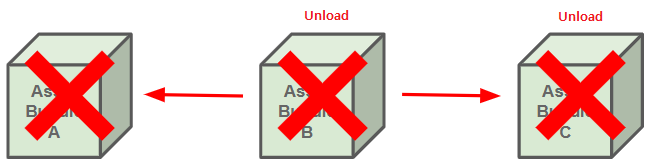
AssetBundles have their own reference count, and the system treats them like Addressables with the assets they contain as dependencies. When you load an asset from a bundle, the bundle's reference count increases and when you release the asset, the bundle reference count decreases. When a bundle's reference count returns to zero, that means none of the assets contained in the bundle are still in use. Unity then unloads the bundle and all the assets contained in it from memory.
In this example, the asset isn't unloaded at this point. You can load an AssetBundle, or its partial contents, but you can't unload part of an AssetBundle. No asset in unloads until the AssetBundle is unloaded.
→ 에셋을 Release하더라도 바로 메모리에서 해제되는 것은 아님. 에셋 번들의 Asset을 부분적으로 Unload할 수는 없으며, 번들의 Refenrence Count가 0이 되면 번들이 해제되며 이때 Asset들의 메모리가 해제된다.
The exception to this rule is the engine interface [Resources.UnloadUnusedAssets]. Executing this method in the earlier example causes to unload. Because the Addressables system isn't aware of these events, the Profiler graph only reflects the Addressables ref-counts (not exactly what memory holds).
→ Resources.UnloadUnusedAssets는 예외적으로 번들에서 사용되지 않는 Asset들을 부분적으로 Unload 가능하다고 함. 단, 이는 Addressables에서 제공하는 프로파일러가 인지하지 못하기에 실제 메모리와는 다른 정보가 표기될 수 있다고 함.
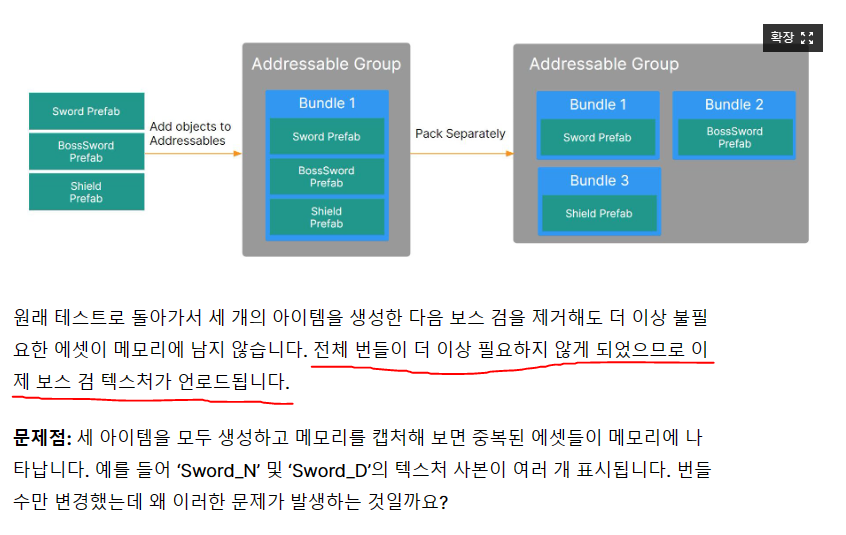
에셋 번들의 종속성이 설정되어 있다면 번들 밖의 에셋을 사용할 때 종속된 에셋 번들을 먼저 로드하고, 해당 에셋에 있는 에셋을 사용한다. 종속성이 잘 지정되어 있다면, Shader를 사용한다고 가정하면 종속된 에셋 번들의 Shader 1개를 공유해서 사용한다.
에셋 번들의 종속성이 설정되어 있지 않다면, 번들 밖의 에셋을 사용할 때 에셋을 복제해서 번들 내부에 포함시킨다. 이 에셋을 다른 에셋 번들이 참조할 수 없기 때문에 이런 복제를 반복하는 에셋 번들의 수만큼 에셋이 복제된다. 이 경우 똑같은 Shader가 10개 이상 메모리에 적재되는 경우도 생긴다.
링크 내부에 Per-Bundle Compression Example이 나와있는데, 해당 부분을 참고하면 된다.
using UnityEditor;
using UnityEditor.Build.Content;
using UnityEditor.Build.Pipeline;
using UnityEditor.Build.Pipeline.Interfaces;
public static class BuildAssetBundlesExample
{
// New parameters class inheriting from BundleBuildParameters
class CustomBuildParameters : BundleBuildParameters
{
public Dictionary<string, BuildCompression> PerBundleCompression { get; set; }
public CustomBuildParameters(BuildTarget target, BuildTargetGroup group, string outputFolder) : base(target, group, outputFolder)
{
PerBundleCompression = new Dictionary<string, BuildCompression>();
}
// Override the GetCompressionForIdentifier method with new logic
public override BuildCompression GetCompressionForIdentifier(string identifier)
{
BuildCompression value;
if (PerBundleCompression.TryGetValue(identifier, out value))
return value;
return BundleCompression;
}
}
public static bool BuildAssetBundles(string outputPath, bool useChunkBasedCompression, BuildTarget buildTarget, BuildTargetGroup buildGroup)
{
var buildContent = new BundleBuildContent(ContentBuildInterface.GenerateAssetBundleBuilds());
// Construct the new parameters class
var buildParams = new CustomBuildParameters(buildTarget, buildGroup, outputPath);
// Populate the bundle specific compression data
buildParams.PerBundleCompression.Add("Bundle1", BuildCompression.DefaultUncompressed);
buildParams.PerBundleCompression.Add("Bundle2", BuildCompression.DefaultLZMA);
if (m_Settings.compressionType == CompressionType.None)
buildParams.BundleCompression = BuildCompression.DefaultUncompressed;
else if (m_Settings.compressionType == CompressionType.Lzma)
buildParams.BundleCompression = BuildCompression.DefaultLZMA;
else if (m_Settings.compressionType == CompressionType.Lz4 || m_Settings.compressionType == CompressionType.Lz4HC)
buildParams.BundleCompression = BuildCompression.DefaultLZ4;
IBundleBuildResults results;
ReturnCode exitCode = ContentPipeline.BuildAssetBundles(buildParams, buildContent, out results);
return exitCode == ReturnCode.Success;
}
}
내부에 요런 코드가 있는데, BundleBuildParameters를 상속받은 CustomBuildParameters Class를 정의한다.
안에 있는 PerBundleCompression에는 에셋 번들의 이름과 해당 번들의 압축 방식을 저장하면 된다.
public override BuildCompression GetCompressionForIdentifier(string identifier)
{
BuildCompression value;
if (PerBundleCompression.TryGetValue(identifier, out value))
return value;
return BundleCompression;
}
또, 내부에는 GetCompressionForIdentifier가 override되어 선언되어 있는데, ContentPipeline.BuildAssetBundles는 빌드를 할 때 번들마다 GetCompressionForIdentifier()를 호출해서 압축 방식을 판단한다. (해당 함수 내부에서 Log를 찍어주면 빌드 이후에 번들마다 호출되는 것을 확인할 수 있다.) 압축 방식이 따로 지정되어있지 않으면 BundleCompression을 반환한다. BundleCompression은 Default 압축 방식을 넣어주면 된다.
이렇게 하면 압축 방식이 달라서 생기는 Dependencies 관련 문제는 말끔히 해결이 된다.
단, BuildPipeline과 다르기 때문에 주의해야할 점이 몇 가지 있다.
1-2-1. Scriptable Build Pipeline을 사용하면 BuildePipeline과는 다르게 Manifest파일이 나오지 않는다.
기존에 Manifest 파일을 사용하여 처리를 하고 있던 부분이 있다면, 그 부분들을 전부 수정해줘야 한다.
IBundleBuildResults인 results에 Manifest에 기록되던 Dependencies나, Hash, CRC 등의 값이 저장되기 때문에 해당 정보를 따로 파일에 저장해서 활용하면 된다.
1-2-2. Scriptable Build Pipeline을 사용하여 에셋을 빌드하면, 에셋을 로드할 때 대소문자를 엄격하게 구분한다.
아마 대소문자가 다른 에셋을 만들 것을 염두에 둔 것인지는 모르겠는데... SBP is strict about the rule: "what you pass in is exactly what you get out". 라고 하니... 뭐 그런가보다.
AssetBundle Browser로 확인해보면 BuildPipeline으로 빌드한 경우 에셋의 Path가 전부 소문자로 되어있는데, ContentPipeline으로 빌드한 경우 실제 경로와 대소문자 구분이 똑같다.
1-2-3. Scriptable Build Pipeline을 사용하면 빌드한 에셋 번들을 삭제해도 다시 빌드하지 않고, 캐시를 활용한다.
일반 BuildPipeline을 사용하면 빌드된 번들을 삭제하면 처음부터 다시 빌드를 하는 것 같은데, ContentPipeline의 경우 Library/BuildCache에 빌드 정보가 캐시되어 빌드를 굉장히 금방 끝낸다. 다만 여기서 문제가 바뀐 부분만 빌드를 하기 때문에 쉐이더를 컴파일하지 않아서 Shader Stripping을 수정해도 적용되지 않을 수 있다. 캐시 정보를 삭제하거나, 이건 번거로우니 IBuildParameters.UseCache = false; 를 사용해서 강제로 처음부터 다시 빌드를 하게 만들어주면 된다.
SBP(Scritable Build Pipeline)의 Shader Stripping에 대한 포럼의 글이 있다.
나의 경우, 기존에는 70MB 수준이던 Shader 총 용량이 210MB로 증가했다.
나도 해당 내용을 참고해서 BuildPipeline을 사용했을 때와 ContentPipeline을 사용했을 때 남은 Keywords를 비교해봤다.
FOG_EXP2와 SHADOWMASK? 2개의 키워드가 추가로 엄청나게 많은 비중을 차지하는 것을 발견했고, 해당 키워드들을 Shader Stripping 목록에 추가해서 지웠고, 90MB로 용량을 대폭 줄일 수 있었다.
처음에는 Player Settings의 Graphics내의 Shader Stripping에 있는 키워드들이라 여기서 지워주는 처리를 안 해주는 것이 아닌가, 생각을 했는데 아까 실험을 몇 가지 해보니 FOG_EXP는 제대로 지워주는 것 같아서 굉장히 헷갈린다. 월요일에 한 번 더 확인해볼 생각이다.
하지만 여전히 90MB로 기존에 비해 30% 가량 큰 용량을 차지하고 있는데, 일부 쉐이더의 용량이 다르다는 문제가 있다. ShaderX라는, Shader를 암호화 해주는? 기능을 사용하는 Shader인데, 분명 사용하는 키워드의 수가 이전과 동일하고 Pass 수도 동일한데 용량 차이가 2배 이상 난다. Pass 내에서 사용하는 키워드의 수가 차이가 나는 건가? 싶기도 한데... log shader compilation 기능을 사용해서 확인해보기는 했지만 경우에 따른 변수가 있어서 다시 확인을 해봐야 할 것 같다. IPreprocessShaders.OnProcessShader에서도 확인해봤지만 BuildPipeline은 이게 요상하게 많이 호출되어서 확인하기도 어렵다. RenderDoc도 사용해봤지만 별 차이를 발견하지는 못했다. 아무튼 용량에 차이가 있다는 것은 Shader Stripping의 방식에 뭔가 차이가 있다는 것인데 Shader 내부를 직접 볼 수가 없어서 정보가 굉장히 부족하다보니 하나씩 삽질을 해가면서 파악을 하고 있다. 이 문제를 해결하면 아마 여기에 추가로 적을 것이라고 생각한다. 위의 포럼에도 내용을 보탤 수 있으면 좋을 것 같다. 아마도 ContentPipeline이 추가된 이후에, Addressable이 추가되어서 ContentPipeline에 대한 지원이 부실하고, 사용하는 사람의 수가 적기 때문에 내용이 적은 것 같은데... Addressable로 업그레이드 할 수 있으면 굉장히 좋겠다는 생각이 든다.
내용을 쓰다보니 Shader Stripping에 대한 내용도 적으면 좋겠다는 생각이 들기는 하는데, 현재 사용하는 Shader Stripping에 대한 기능을 업그레이드 할 계획을 세우고 있어서 해당 시스템을 구축하고 나서 내용을 적을 예정이다.
+Scriptable Build Pipeline을 사용하면 IPreprocessShaders가 제대로 호출되지 않는데, SBP는 기존의 BuildPipeline과는 다르게 Library/BuildCache 폴더에 캐시를 해두고 빌드를 하기 때문에 빌드한 에셋 번들을 날려도 캐시된 데이터를 바탕으로 에셋 번들을 빌드하기 때문인 것으로 생각된다. 때문에 Shader가 바뀌지 않는 이상 Shader를 다시 컴파일하지 않고, 이에 따라 IPreProcessShaders가 제대로 호출되지 않는 것이다. 이를 해결하기 위해서는 BuildCache 폴더를 삭제한 후에 다시 빌드할 수도 있지만, 이 폴더는 파일 수가 굉장히 많고 용량이 크기 때문에 IBuildParameters.UseCache = false; 를 해주면 조금 더 간편하게 IPreProcessShaders를 호출할 수 있다.
assetBundle.Unload(false)를 하면 로드된 리소스를 유지한 채로 meta 정보를 날리는데, 이 meta 정보에는 리소스가 메모리 상 어디에 로드되었는지가 기록되기 때문에 이걸 날려버리고 다시 로드를 하면 기존의 리소스를 참조하지 못하고 새로운 리소스를 로드하게 된다.(라고 들었다) 즉, 메모리 상에 에셋이 중복되어 생성되는 것이다.
assetBundle.Unload(true)를 하면 로드된 리소스까지 같이 날려버리지만, 사용하고 있는 경우 마젠타 색으로 표시될 것이다.
즉, 어느 경우든 "해제하는 에셋 번들에서 에셋을 사용하고 있지 않다" 는 것이 확실해야 문제가 발생하지 않는다.
이것을 확인할 수 있는 방법은 Reference Count를 기록하여 0이 되었는지 확인하는 것인데, BuildPipeline 등은 이 기능을 코드로 직접 구현해줘야 한다. 참고로 Addressable은 이걸 알아서 해주면서 참조가 0이되면 알아서 해제까지 해주기 때문에 Addressable을 사용하는 것이 굉장히 좋겠다.
다음 주 회사에서 하는 스터디 내용으로 Addressable에 대한 내용을 준비해 갈 예정인데, 여태 알아본 바로는 우리가 사용하는 기본 AssetBundle의 굉장한 상위 호환으로 느껴진다. 준비를 잘 해가서 Addressable로 업그레이드하면 굉장히 좋겠다는 점을 어필하고 싶다. 아마 Addressable에 대해 공부한 내용을 블로그에도 적을 것 같다.